介绍
机器视觉CV和人工智能AI在生产和生活中的运用越来越多。既有应用于工业检测的专业,功能强大,性能稳定的工业相机,也有用于教学用途的性能较弱,分辨率较低的开源视觉镜头。工业相机价格昂贵,而且需要非常强的专业学习才能真正的使用,而开源的视觉镜头,性能孱弱,分辨率低,在进行稍复杂的应用的时候,很难达到实时要求。
znzpi使用基于工业相机的算法和控制核心,并使用具有神经网络协处理器的高性能的处理器,将openmv的python接口部分进行了移植,并将视觉部分开源。简化使用复杂度的同时,又具有价格低廉的优点。
非常适合机器视觉和人工智能学习和产品开发。
本教程详细介绍znzpi在硬件、软件、应用、算法以及算法移植。适用于专注应用层面,适用python,快速完成开发的开发者。而进行更底层的芯片+SDK+C的开发者,请参考另外一个开发手册。
可以在优微视技术的官方网站上了解最新的硬件和使用文档。
也可以在www.gitee.com的开源代码中了解最新开发版本的硬件和软件。
硬件
硬件特性
-
CPU:大核:1.5GHz ARM Cortex-A7及NEON和FPU, 小核:400MHz RISC-V
-
NPU:0.5 Tops 支持INT8,INT16;支持TensorFlow,TF-lite,Pytorch,Caffe,ONNX,MXNet keras,DarkNet
-
128MB/256MB DDR3
-
128M/256M Nand flash
-
最高500万像素sensor输入
-
4Kp30 h.265 h.264编码
-
4Kp30 h.265 h.264解码
-
LCD显示
-
USB2.0 OTG
-
图传延时小于200毫秒
产品图片
产品图片:
接口定义
特别提醒,无论是使用网络尾线,type-c,插针电源输入只支持5V,网络尾线不能接12V电源,否则必烧板子
侦侦拍znzpi rv1106 接口定义:



RGB屏接口定义:

购买
购买链接:
[淘宝侦侦拍RV1106](https://item.taobao.com/item.htm?ft=t&id=731789779188)
[淘宝侦侦拍AOI店](https://shop109794194.taobao.com/)
[官网优微视技术](http://www.youvtec.com/)
软件
相机固件
基于于工业相机同源的算法内核,稳定性高,可以完成实时检测任务。
图传码流经过h.264硬件压缩,图传延时小于200毫秒,这在需要实时操控的场景下非常重要,例如在具有无线图传的需要手工操控机器人的场景中,小于200毫秒的延时,几乎感觉不到操作到机构动作差异。
支持基于python的相机程序开发。
IDE可以从官方网站下载
从youvtec.com上下载编程IDE,
[znzpi_ide](http://www.youvtec.com/download/znzpi_ide.exe)
[znzpi_ide](http://youvtec.com/download/znzpi_ide.zip)
开发前的准备
安装硬件
将网络接入到局域网路由器,将OTG的usb线插入PC的usb口。
如果使用的是Python调试的面,此时会在pc上看到一个名为YVCam的MTP设备,一个 CDC串口设备 和一个UVC Camera。如果没有出现新设备,需要安装相关驱动。



如果插入的是系统调试串口的面会出现一个 CH340的串口设备 。

如果没有出现新设备提示,请更换USB口尝试。
要判断板子是否正常,可以从板子上的指示灯判断其状态:
-
蓝色灯亮起,电源正常。
-
红色灯亮起,软件系统(Linux)和驱动正常。
-
红色灯闪烁两次,Python环境创建正常,程序脚本被加载(不论程序中是否有错误)。
-
红灯经过上述过程后熄灭,说明Python程序已经启动。
驱动安装
win11上右键单击开始菜单,在弹出的菜单上选择设备管理器;win10上右键单机电脑,在管理,系统工具中选择设备管理器。
在未知设备中找到MTP设备,此时是没有安装正确驱动的状态。右键单击后选择更新驱动程序,选择浏览计算机以查找驱动程序软件。
选择从计算机的设备驱动列表中选取;在常见硬件类型(H);选择便携设备;最后在兼容硬件(IC);选择MPT USB 设备;单击下一步完成安装。
在win10和win11在MTP USB设备的选择上稍有不同,浏览各个选型找到MTP USB设备即可。
打开资源管理器
在其他设备的MTP上右键,更新驱动程序
选择浏览我的电脑以查找驱动程序

选择从我的计算机上的可用驱动程序列表中选取,并下一步

从设备列表中找到便携设备

点便携设备,并下一步

从设备中选标准MTP设备

在标准MTP设备中选MTP USB设备,并下一步

忽略警告,并点击是按钮

安装完成后,点击关闭

在设备管理器中,会看到一个便携设备 YVCAM

CDC-ACM的驱动在win10和win11上是免驱的,win7需要相应的inf文件。
UVC Camera 可以选择两种驱动方式,Microsoft的MediaFoundation和WinUSB。
MediaFoundation在win10和win11上也是免驱的。不需要额外安装驱动。
如果MediaFoundation无法获取到图像,可以选择WinUSB驱动(AI相机固件版本0.7.16或更高)。
这个驱动需要使用zadig.exe(https://zadig.akeo.ie/)设置。
打开zadig.exe,并在option菜单,list all device
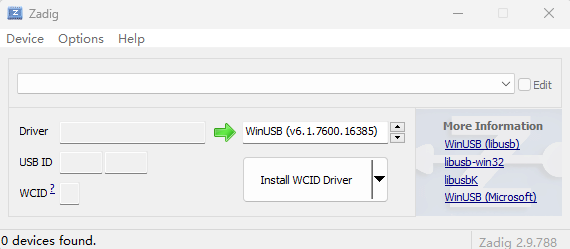
选择usb id为2207+0019+0的设备,并点击ReplaceDriver按钮,完成WinUSB驱动的安装。
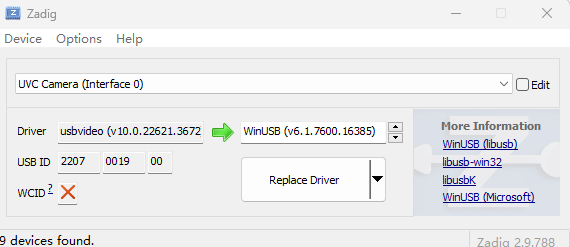
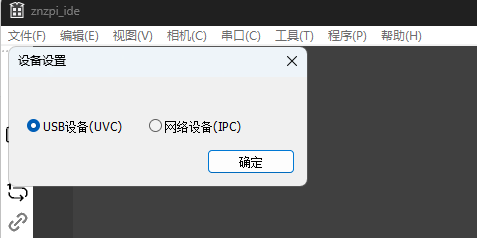
在znzpi_ide软件上,选择对应的驱动方式,菜单→相机→设备设置,选择WinUSB驱动。
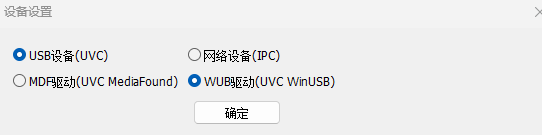
使用方式
侦侦拍R3支持多种访问方式:
-
只使用USB,这种模式通过USB OTG虚拟的MTP,串口和UVC直接进行程序和图传的访问
-
使用Eth网络,这种模式可以将USB按调试串口的面插入,进入linux系统。
-
使用Wifi网络,和使用Eth相同,可以减少接入有线网络。
使用USB,以UVC设备访问相机,在第一次上电的时候,windows系统的驱动加载比较慢,需要耐心等待其完成。 需要在windows的驱动管理器中,强制其扫描硬件,以完成驱动的加载。
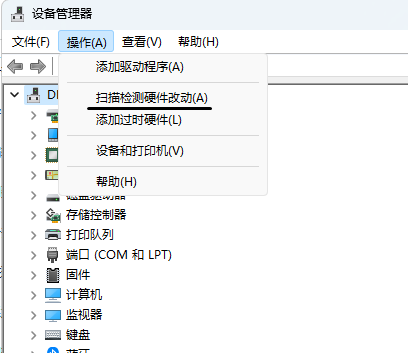
扫描过程中会有如下界面
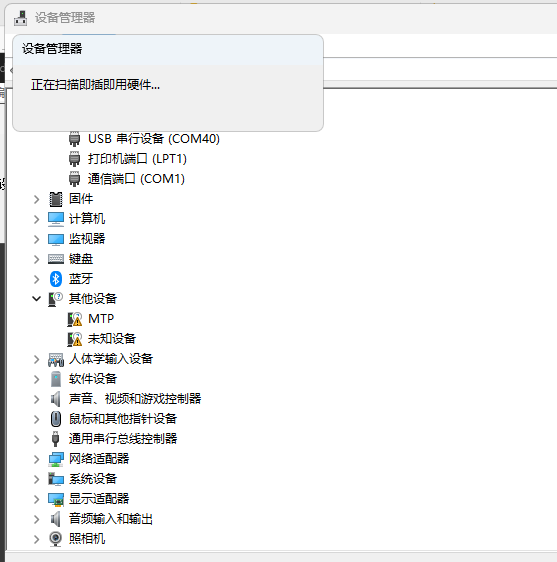
当其消失的时候,说明windows的驱动已经加载完成,此时可以打开znzpi_ide.exe,在设备设置中,选择UVC设备。
在znzpi_ide中默认按第一种方式连接AI相机,当自动检查MTP,串口和UVC设备失败后,会自动按Eth和Wifi方式连接板子。
也可以在znzpi_ide中设置设备,设置是否优先使用USB连接。
在znzpi_ide中的输出显示窗口,既可以看Python的打印输出信息,也可以通过这个窗口,发送如下命令
-
trigger 触发运行一次
-
get_script 从板子下载程序到编辑器
-
reset 将板子重启
-
sensor 获取sensor的当前设置,(注意,这个命名的结果不会在窗口显示)。
在窗口中输入上述命令,并回车后,会将上述命令发送到板子并执行。
修改板子IP地址
板子的默认IP地址为192.168.0.38,这可能和开发环境的IP地址的网段不同。如果需要修改板子的IP地址,可以用如下的几种用方法来修改。
-
使用znzpi_ide进行修改
-
使用手机其他有wifi的设备,寻找热点YOUVTEC_WIFI,使用默认密码88888888链接,并用浏览器连接192.168.38,会出现实时图像,可以在设置页面修改默认IP
-
安装完成成MTP驱动后,用typec接入PC,其中typec一面的功能为模拟U盘和串口,会出现一个YVCAM的设备,通过修改里面的vod_config.json文件中的inet等设置IP地址。
-
通过typec的另外一面为调试串口,进入linux后修改/userdata/cam_conf/vodconfig.josn来修改板子的默认IP地址
在下面会有使用MTP模拟U盘修改IP的具体方法
使用znzpi_ide 修改板子IP
在typec在python调试一面的时候,znzpi_ide可以通过在菜单: 相机→ip设置,对板子的ip进行修改。
这是通过将修改的命令用python调试串口,发送到板子上并执行的。因而使用这个方法,一定要将USB的typec插在正确的面。
修改板子的AI相机的python程序
板子的默认python程序是一个色块搜索程序,如果需要对板子的程序进行修改,可以通过如下的几种方法。
-
在typec接入PC后,其中typec一面的功能为模拟U盘和串口,会出现一个YVCAM的设备,通过使用文本编辑器修改里面的init.py,这种方法修改的python程序不会立即运行,需要重启板子才能运行。
-
使用有线网络或wifi连接上板子后,使用znzpi_ide进行编程和上传到板子,这种方法上传的程序会替换原有的程序,并立即运行。
-
使用typec的另外一面的调试串口,进入linux后修改/userdata/cam_conf/jobs/init.py来修改,这种方法修改后也不会立即运行新的python程序,需要重启后才会运行。
使用手机修改板子IP
一 手机连接板子WIFI

二 浏览器输入板子默认IP地址

三 进入预览

四 进入设置

使用MTP修改配置和程序
在出现的新存储设备中,有znzpi的默认设置文件config.json和默认的程序脚本init.py
znzpi的默认IP地址是192.168.0.38,wifi默认密码是88888888, 可以通过用文本编辑器,如ultraedit或记事本,修改vod_config.json,来修改IP地址。
也可以离线编辑init.py进行重新编程。
重启后,znzpi将使用新IP地址。可以通过浏览器输入IP地址 http://192.168.0.38 来访问图传的视频。
也可以使用vlc等播放软件,输入 rtsp://192.168.0.38/live 来访问。
如果使用的是wifi,znzpi的wifi默认模式是ap热点,使用手机等终端,连接开发板的热点YOUVTEC_WIFI的,登录后在浏览器中输入开发板的ip地址192.168.0.38,即可看到实时视频,由于手机的浏览器缓存等,会有一定的延迟,浏览时间越长,延迟越大。
如果需要实时浏览,需要使用znzpi_ide.exe。
使用AI相机固件,板子默认启动摄像头socket_http程序。可以通过网络连接,在浏览器预览画面 打开浏览器输入板子ip
使用AI相机固件,通过如下方法修改IP
板子已设置静态ip:192.168.0.38。需要更改ip则在板子
中/userdata/cam_conf/vod_config.json 修改即可
inet字段设置为
-
ap : WiFi使用热点模式
-
wifi: 使用sta模式
-
static: 使用以太网模式
以太网使用了8pin的座子,需要配合相应的尾线使用,尾线在侦侦拍的网店有销售,
$ cat /etc/init.d/S99mpp /root/auto_run.sh /*znzpi的主程序*/ .... /memdisk/setup/bin/socket_httpd ....
热点模式
需要注意,wifi需要安装天线使用,虽然近距离没有天线也可以看到wifi,但信号会非常差,
由于没有安装天线,会导致大量的数据重传,在图传应用中,会出现延迟大,图像花屏等。
板子默认使用ap模式,使用的wifi节点是p2p0,并和eth0做了桥接,也就是是说,用以太网访问和用wifi的ap热点方式访问开发板,开发板的默认ip都是一样的,
如果需要通过串口,临时修改板子的ip地址,使用ifconfig只修改br0即可。
以手机访问开发板为例,在手机上搜索SSID名字为YOUVTEC-WIFI的热点,使用密码88888888进行连接。
连接完成后,在手机浏览器中输入开发板的ip地址,192.168.0.38,即可看到预览的视频。
由于浏览器有较大的缓存,在浏览的时候会有较大的延迟。如果需要实时预览,请在pc上使用侦侦拍提供的znzpi_ide.exe进行实时预览。
IDE可以从官方网站下载
从youvtec.com上下载编程IDE,
[znzpi_ide](http://www.youvtec.com/download/znzpi_ide.exe)
[znzpi_ide](http://youvtec.com/download/znzpi_ide.zip)
sta 模式
开发板同时支持以sta模式,连接wifi路由器,打开wifi节点
sta的设置在/userdata/cam_conf/vod_config中,修改wifi_sta相应的字段, 并将inet设置为"wifi",重启开发板则会使用wlan0,进入sta模式。
vod_config.json中的字段信息会被解析并写入/userdata/cam_conf/wpa_supplicant.conf。 如果手工修改wpa_supplicant.conf,在下一次开发板上电的时候,会根据vod_config.json改写。
ssid和key一定要正确,否则连接不会成功。
sta模式的wifi和eth0会进行绑定,产生bond0。eth0和wlan0进行负载均衡处理,是为了保证发送的图传数据具有单一地址。修改ip的时候需要修改bond0即可。单独修改wlan0,会导致联网找不到网页和图传视频。
特别提醒,由于sta模式需要和路由器连接。中间的环节多,干扰多,网络带宽大打折扣。这种模式下不适合进行实时图传。会出现在znzpi_ide中的视频特别卡,点击运行的反应也会变慢。
在使用znzpi_ide进行视觉开发时,建议使用网络尾线进行有线连接,
如果没有自动获取到 IP 地址,则执行
$ udhcpc -i bond0
下载IDE
IDE具有专业的python开发编辑器,以及实时图传客户端。
从youvtec.com上下载编程IDE,
[znzpi_ide](http://www.youvtec.com/download/znzpi_ide.exe)
[znzpi_ide](http://youvtec.com/download/znzpi_ide.zip)
从gitee.com上下载 [znzpi_ide](https://www.gitee.com/muzedavid/znzpi_ide/release/znzpi_ide.exe)
连接相机,在工具栏菜单中,选相机,输入相机IP地址。 相机连接后可以在右侧的窗口看到实时的图像。
连接调试串口,在工具栏菜单中,选串口,输入新增加测串口,设置波特率为115200
下载相机中的程序用于编辑,在工具栏菜单中,使用下载菜单,此时在编辑器中会看到已有的程序。可以进行编辑和保存 也可以使用打开菜单,打开在PC中的python程序代码。
-
程序编辑器
-
图传客户端
-
阈值选择工具
-
串口调试工具
-
ROI选择工具
在工具栏和菜单栏,可以使用下载菜单,将板子上的python程序下载到编辑器中,也可以使用上传菜单,将编辑器中的程序上传到板子。 在这里板子可以理解为一个server,而ide是一个client。
python基础
作为micropython的一个移植,支持python的语法和用法。具体的用法,可以参考python相关的编程教程。
也有如下所述的一些独特用法。
作为最基本的debug手段,可以使用print函数来获取信息。 调用方式为:
print(val)
数组和列表
tuple 类型操作,在znzpi的诸多函数中,返回的类型是tuple, 要获得数组的长度可以使用 count()函数,
遍历各个项可以使用:
for it in items:
print(it)
主函数
与c/c++程序的main函数类似,在znzpi的python程序中,使用loop()作为主函数。
定义的loop函数,在每次被触发,以及连续运行的时候,会被调用,
在主函数之外的python代码,会在程序加载的时候调用,完成初始化工作。在下面的示例代码中, import 相关的代码,只在加载的时候调用一次。而loop定义内的代码,会被多次调用。
import image
import sensor
def loop():
print('hello world')
异常处理
当python代码中出现异常,如调用了不存在的函数,使用不存在的变量等,会在调试串口,打印相关的信息。 这些信息包括存在错误的行,以及错误的类型以及其具体错误等。 方便进行代码修改。
经典应用
图像获取
import image
import sensor
sensor.reset()
def loop():
img = sensor.snapshot()
print(img)
loop函数,在自动模式下,会被循环调用,用于实时处理。在手动模式下,当被触发的时候会被调用。 print(img),会打印图像的信息,诸如宽度、高度、格式等信息。
画直线和矩形
import image
import sensor
sensor.reset()
def loop():
img = sensor.snapshot()
img.draw_line((10,10,200,500), color=(255,0,0), thickness=4)
img.draw_rectangle((640,220,640,640), color=(255,0,0), thickness=4)
画图像
import image
import sensor
sensor.reset()
img = sensor.snapshot()
def loop():
img = sensor.snapshot()
img.draw_image(img,(0,0),x_scale=0.5,y_scale=0.5)
print('ok')
线提取
import image
import sensor
sensor.reset()
def loop():
img = sensor.snapshot()
lines = img.find_lines((640,220,640,640))
for ln in lines :
img.draw_line(ln.line(),color=(255,0,0), thickness=4)
圆提取
import image
import sensor
sensor.reset()
def loop():
img = sensor.snapshot()
circles = img.find_circles(roi=(442,172,219,132))
print(circles)
for ln in circles :
img.draw_circle(ln.circle(),color=(255,0,0), thickness=4)
色块获取
import image
import sensor
sensor.reset()
def loop():
img = sensor.snapshot()
thr = (120,159,90,117,104,156)
blobs = img.find_blobs([thr],roi=(429,162,250,140))
for ln in blobs :
img.draw_rectangle(ln.rect(),color=(255,0,0), thickness=4)
识别二维码
import image
import sensor
sensor.reset()
def loop():
img = sensor.snapshot()
for code in img.find_qrcodes() :
x = code.x()
y = code.y()
w = code.w()
h = code.h()
rc = code.rect()
img.draw_rectangle(rc, color=(255,0,0), thickness=4)
print(x,y,w,h)
print(rc)
print(code.payload())
img.draw_string(x,y,code.payload())
AprilTag标记跟踪
AprilTag的种类
AprilTag的种类叫家族(family),有下面的几种:
-
TAG16H5 → 0 to 29
-
TAG25H7 → 0 to 241
-
TAG25H9 → 0 to 34
-
TAG36H10 → 0 to 2319
-
TAG36H11 → 0 to 586
-
ARTOOLKIT → 0 to 511
也就是说TAG16H5的家族(family)有30个,每一个都有对应的id,从0~29。
那么不同的家族,有什么区别呢?
比如说TAG16H5的有效区域是4 x 4的方块,那么它比TAG36H11看的更远(因为他有6 x 6个方块)。但是TAG16H5的错误率比TAG36H11高很多,因为TAG36H11的校验信息多,所以,如果没有别的理由,推荐用TAG36H11。
程序
# AprilTags Example
#
# This example shows the power of the OpenMV Cam to detect April Tags
# on the OpenMV Cam M7. The M4 versions cannot detect April Tags.
import sensor, image, time, math
sensor.reset()
sensor.set_pixformat(sensor.GRAYSCALE)
sensor.set_framesize(sensor.VGA) # we run out of memory if the resolution is much bigger...
sensor.skip_frames(time = 2000)
sensor.set_auto_gain(False) # must turn this off to prevent image washout...
sensor.set_auto_whitebal(False) # must turn this off to prevent image washout...
clock = time.clock()
# Note! Unlike find_qrcodes the find_apriltags method does not need lens correction on the image to work.
# The apriltag code supports up to 6 tag families which can be processed at the same time.
# Returned tag objects will have their tag family and id within the tag family.
tag_families = 0
tag_families |= image.TAG16H5 # comment out to disable this family
tag_families |= image.TAG25H7 # comment out to disable this family
tag_families |= image.TAG25H9 # comment out to disable this family
tag_families |= image.TAG36H10 # comment out to disable this family
tag_families |= image.TAG36H11 # comment out to disable this family (default family)
tag_families |= image.ARTOOLKIT # comment out to disable this family
# What's the difference between tag families? Well, for example, the TAG16H5 family is effectively
# a 4x4 square tag. So, this means it can be seen at a longer distance than a TAG36H11 tag which
# is a 6x6 square tag. However, the lower H value (H5 versus H11) means that the false positve
# rate for the 4x4 tag is much, much, much, higher than the 6x6 tag. So, unless you have a
# reason to use the other tags families just use TAG36H11 which is the default family.
def family_name(tag):
if(tag.family() == image.TAG16H5):
return "TAG16H5"
if(tag.family() == image.TAG25H7):
return "TAG25H7"
if(tag.family() == image.TAG25H9):
return "TAG25H9"
if(tag.family() == image.TAG36H10):
return "TAG36H10"
if(tag.family() == image.TAG36H11):
return "TAG36H11"
if(tag.family() == image.ARTOOLKIT):
return "ARTOOLKIT"
def loop():
clock.tick()
img = sensor.snapshot()
for tag in img.find_apriltags(families=tag_families): # defaults to TAG36H11 without "families".
img.draw_rectangle(tag.rect(), color = (255, 0, 0))
img.draw_cross(tag.cx(), tag.cy(), color = (0, 255, 0))
print_args = (family_name(tag), tag.id(), (180 * tag.rotation()) / math.pi)
print("Tag Family %s, Tag ID %d, rotation %f (degrees)" % print_args)
print(clock.fps())
模板匹配
物体识别
物体识别使用了znzpi的硬件加速人工神经网络。
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.OBJECT_DETECT)
print(ml)
roi = (0,0,600,600)
def loop():
#img = sensor.snapshot()
img = image.Image('/userdata/module/bus.jpg')
#img.draw_image(img,(0,0))
#img.draw_rectangle(roi, color=(0,0,255), thickness=4)
out = ml.forward(img,roi=roi)
for it in out:
print(it.rect())
img.draw_rectangle(it.rect(),color=(0,255,0), thickness=4)
人脸识别
以图像文件为输入源
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.FACE_DETECT)
print(ml)
img = image.Image('face.jpg')
#roi = (820,320,640,640)
roi = (0,0,612,344)
def loop():
#img = sensor.snapshot()
print(img)
img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
for it in out:
print(it.rect())
img.draw_rectangle(it.rect(),color=(255,0,0), thickness=4)
以实时图像为输入源
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.FACE_DETECT)
print(ml)
roi = (620,220,640,640)
def loop():
img = sensor.snapshot()
#img.draw_rectangle(roi, color=(0,0,255), thickness=4)
out = ml.forward(img,roi=roi)
for it in out:
print(it.rect())
img.draw_rectangle(it.rect(),color=(0,255,0), thickness=4)
视觉算法函数
绘图函数B
image模块支持在图传的图像中绘制图形,如直线、圆等。下面对绘图函数以及参数进行详细说明。
draw_line
image.draw_line(x0, y0, x1, y1[, color[, thickness= 1]]) 绘制一条从 (x0, y0) 到 (x1, y1 ) 的直线。 x0、y0、x1、y1: 起始点坐标和终点坐标,可以单独使用 x0、y0、x1、y1,也可以使用元组 (x0, y0, x1, y1) color: 可以使用 RGB888值,或 RGB888 元组。默认为白色。 thickness: 控制线条的粗细(以像素为单位)。 返回图像对象
draw_rectangle
image.draw_rectangle(x, y, w, h[, color[, [thickness =1, fill = False]]]) 绘制一个矩形。 x,y,w,h: 矩形的左上角坐标和宽度高度,可以单独使用 x,y,w,h,也可以使用元组 (x, y, w, h)。 color: 可以使用 RGB888值,或 RGB888 元组。默认为白色。 thickness: 控制线条的粗细(以像素为单位)。 fill: 是否绘制实心矩形,绘制实心矩形,可以将Fill 设置为 True 。 返回图像对象
draw_circle
image.draw_circle(x,y,radius[,color[,thickness=1[,fill=False]]]) 绘制一个圆圈。 x,y,radious: 圆心坐标和圆半径。可以单独使用 x,y,radious,也可以使用元组(x,y,radius)。 color: 可以使用 RGB888值,或 RGB888 元组。默认为白色。 thickness: 控制边缘的thickness(以像素为单位)。 fill: 如果要绘制实心圆形,可以将Fill 设置为 True 返回图像对象。
draw_ellipse
image.draw_ellipse(cx, cy, rx, ry, rotation[, color[, thickness= 1[, fill = False]]]) 绘制一个椭圆。 cx,cy,rx,ry: 椭圆的圆心。可以使用 cx,cy,rx,ry 和rotation(以度为单位),也可以使用元组(cx,yc,rx,ry,rotation)。 color: 可以使用 RGB888值,或 RGB888 元组。默认为白色。 thickness: 控制边缘的thickness(以像素为单位)。 fill: 如果要绘制实心椭圆,可以将Fill设置为 True。 返回图像对象。
draw_string
image.draw_string(x, y, text[, color[, scale=1[, x_spacing=0[, y_spacing=0[, mono_spaceTrue[, char_rotation=0[, char_hmirror=False[, char_vflip=False[, string_rotation=0[, string_hmirror=False[, string_vflip=False]]]]]]]]]]]) 在位置 (x, y) 绘制文本。 x,y: 起始坐标,可以单独使用 x、y 或使用元组 (x, y)。 text: 是要输出的字符串。并将行尾将光标移动到下一行。\n\r\r\n color: 可以使用 RGB888值,或 RGB888 元组。默认为白色。 scale: 缩放系数,可以增加以放大或缩小文本的大小。可以使用大于 0 的整数或浮点值。 x_spacing: 可以在 cahracters 之间添加(如果为正)或减去(如果为负)x 像素。 y_spacing: 可以在 cahracters 之间添加(如果为正)或减去(如果为负)y 像素(对于多行文本)。 mono_space: 默认值为 True,强制文本间隔固定。设置 False 以获得非固定宽度字符间距。 char_rotation 可以用0,90,180,270来旋转字符串中的每个字符。 char_hmirror: 如果设置为 True,将水平镜像字符串中的所有字符。 char_vflip: 如果设置为 True,将垂直翻转字符串中的所有字符。 string_rotation: 可以用0、90、180、270来旋转整个字符串。 string_hmirror: 如果设置为 True 将水平镜像整个字符串。 string_vflip: 如果设置为 True 将垂直翻转整个字符串。 返回图像对象。
draw_cross
image.draw_cross(x, y[, color[, size= 5[, thickness = 1]]]) 在位置 x, y 处绘制一个十字。 x,y: 中心坐标,可以使用 x、y 或使用元组 (x, y)。 color: 可以使用 RGB888值,或 RGB888 元组。默认为白色。 size: 控制十字线的大小。 thickness: 控制边缘的thickness(以像素为单位)。 返回图像对象。
draw_arrow
image.draw_arrow(x0, y0, x1, y1[, color[, thickness= 1]]) 上绘制一个从 (x0, y0) 到 (x1, y1) 的箭头。 x0,y0,x1,y1: 箭头的起始坐标和结束坐标,可以使用 x0,y0,x1,y1,也可以使用元组 (x0, y0, x1, y1)。 color: 可以使用 RGB888值,或 RGB888 元组。默认为白色。 thickness: 控制线条的粗细(以像素为单位)。 返回图像对象。
draw_edges
image.draw_edges(image,corners[,color[,size= 0[,thickness= 1[,fill= False]]]]) corners: 绘制blob.corners 等方法返回的角点构成的边缘线。Coners 是包含坐标 x,y 元组的四值元组。例如 [(x1,y1),(x2,y2),(x3,y3),(x4,y4)]。 color: 可以使用 RGB888值,或 RGB888 元组。默认为白色。 size: 如果大于 0 会将角点绘制为以size为半径的圆点 。 thickness: 控制线条的粗细(以像素为单位)。 fill: 需要绘制实心时圆角时,将 Fill 设置为 True。 返回图像对象。
draw_image
image.draw_image(image, x, y[, x_scale=1.0[, y_scale=1.0[, roi=None[, rgb_channel=-1[, alpha=256[, hint=0[, x_size=None[, y_size=None]]]]]]]]]])
在位置 x, y 绘制图像。
x,y: 图像左上角坐标,可以使用 x、y 或元组 (x, y)作为图像左上角位置的坐标。此方法自动处理将传递的图像渲染为目标图像的正确像素格式,同时还无缝处理剪切。
x_scale: 控制绘制的图像在 x 方向(浮点型)上的缩放。如果此值为负数,则图像将水平翻转。
y_scale: 控制绘制的图像在 y 方向(浮点型)上的缩放。如果此值为负数,则图像将垂直翻转。
roi: 是要绘制的源图像的感兴趣区域矩形元组 (x, y, w, h)。这允许您仅提取ROI中的像素,以缩放和绘制目标图像。
rgb_channel: 从彩色图像(如果传递)中提取并渲染到目标图像的 RGB 通道(0=R、G=1、B=2)。例如,如果rgb_channel=1 这将提取源图像的绿色通道,并在目标图像上以灰度绘制该通道。
alpha: 控制要将源图像的多少内容混合到目标图像中。值为 256 将绘制不透明的源图像,而值小于 256 将在源图像和目标图像之间生成混合。0 表示不对目标映像进行任何修改。
hint: 可以是标志的逻辑 OR:
image.AREA:在缩小缩放时使用区域缩放,而不是使用最近邻的默认值。
image.BILINER:使用双线性缩放与最近邻缩放的默认值。
image.BICUBIC:使用双三次缩放与默认的最近邻缩放。
image.CENTER:使正在绘制的图像图像居中 (x, y)。
image.EXTRACT_RGB_CHANNEL_FIRST:在缩放之前执行rgb_channel提取。
image.APPLY_COLOR_PALETTE_FIRST:在缩放之前应用调色板。
image.BLACK_BACKGROUND:设目标图像为黑色。这加快了绘图速度。
x_size: 指定要绘制的图像的大小。如果未指定或未指定,则在内部将设置为等于x_scale 以保持纵横比。
y_size: 指定要绘制的图像的大小。如果未指定或未指定,则在内部将设置为等于y_scale 以保持纵横比。
返回图像对象。
import image
import sensor
sensor.reset()
img = sensor.snapshot()
def loop():
img = sensor.snapshot()
img.draw_image(img,(0,0),x_scale=0.5,y_scale=0.5)
print('ok')
draw_keypoints
image.draw_keypoints(keypoints[,color[,size = 10[,thickness = 1[,fill = False]]]]) 绘制关键点。 keypoints: 递包含 (x, y, rotation_angle_in_degrees) 的三个值元组的列表,以重用此方法绘制关键点字形,这些标志形是具有指向特定方向的线的圆环。 color: 可以使用 RGB888值,或 RGB888 元组。默认为白色。 size: 控制关键点的大小。 thickness: 控制线条的粗细(以像素为单位)。 fill: 如果需要填充,设置为 True 。 返回图像对象。
图像处理函数
load
image.Image(path)
读取 jpeg文件,并存入image中,可用于后面的处理,或作为其他算法的输入。
path : 图片路径
import image
img = image.Image('dog.jpg')
img.draw_image(img,(0,0))
flood_fill
image.flood_fill(x, y[, seed_threshold=0.05[, floating_threshold=0.05[, color[, Invert=False[, clear_background=False[, Mask=None]]]]]]) 从位置 x, y 开始的图像区域做漫水填充。 x,y: 起始位置,可以使用 x、y 或元组 (x, y)。 seed_threshold: 控制田中区域中的任何像素与原始起始像素的阈值。 floating_threshold: 控制填充区域中的任何像素与任何相邻像素的阈值。 color: 可以使用 RGB888值,或 RGB888 元组。默认为白色。 invert: 如果传递为 True 以重新着色泛洪fill连接区域之外的所有内容。 clear_background: 将填充点重新着色的其余像素。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。在满水填充时,仅使用蒙版中设置的像素。 返回图像对象。
mask_rectange
image.mask_rectange([x, y, w, h]) 将图像的矩形部分归零。 如果未提供任何参数,则此方法将图像的中心归零。 返回图像对象。
mask_circle
image.mask_circle([x, y, radius]) 将图像的圆形部分归零。 如果未提供任何参数,则此方法将图像的中心归零。 返回图像对象。
mask_ellipse
image.mask_ellipse([x、y、radius_x、radius_y、rotation_angle_in_degrees]) 将图像的椭圆形部分归零。 如果未提供任何参数,则此方法将图像的中心归零。 返回图像对象。
binary
image.binary(thresholds[,invert=False[,zero=False[,mask=None[,to_bitmap=False[,copy=False]]]]]) 将图像中的所有像素设置二值化,具体取决于像素是否在阈值列表中的阈值范围内。 thresholds: 对于灰度图像,每个元组需要包含两个值 - 最小灰度值和最大灰度值。将仅考虑介于这些阈值之间的像素区域。 对于彩色图像,每个元组需要有六个值(l_lo、l_hi、a_lo、a_hi、b_lo、b_hi) - 分别是 LAB L、A 和 B 通道的最小值和最大值。为了便于使用,此功能将自动修复交换的最小值和最大值。此外,如果元组大于六个值,则忽略其余部分。相反,如果元组太短,则其余阈值处于最大范围。[(lo, hi), (lo, hi), ..., (lo, hi)] 注意 要获取要跟踪的对象的阈值,只需在 IDE 帧缓冲区中选择要跟踪的对象上选择(单击并拖动)即可。然后,直方图将更新为仅位于该区域中。 然后只需记下颜色分布在每个直方图通道中开始和下降的位置。这些将是 您的低值和高值。最好手动确定阈值,而不是使用上限和下四分位数统计信息,因为它们太紧了。 还可以通过在 IDE 中使用阈值设置功能,选择阈值来确定颜色阈值。工具->阈值分析 invert: 反转阈值操作,以便匹配某些已知color边界内的像素,而不是匹配已知color边界之外的像素。 zero: 设置为 True 可改为零阈值像素,并使阈值列表中未受影响的像素保持不变。 mask: 像素级蒙版图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 to_bitmap: 将图像数据转换为二进制位图图像,其中每个像素以 1 位存储。对于非常小的图像,新的位图图像可能不适合原始图像的内部,需要使用copy扩充 copy: 如果 True 在堆上创建二值化映像的副本,而不是修改源映像。 注意 位图图像类似于只有两个像素值(0 和 1)的灰度图像。此外,位图图像被打包,使得它们每像素仅存储1位,使它们非常小。图像库允许在传感器的所有位置使用位图图像,灰度图。可以使用彩色图像。但是,在位图图像上应用许多操作没有任何意义,因为位图图像只有 2 个值。建议在操作中使用位图图像作为值。最后,位图图像像素值 0 和 1 在应用于图像处理时被解释为黑白。与灰度图或彩色图像,进行运算是,会自动转换。 返回图像对象。
invert
image.invert() 二进制反转图像中的所有像素值。 返回图像对象。
b_and
image.b_and(image[,mask = None]) 将图像与另一个图像做逻辑与。 image: 可以是图像对象。 mask: 像素级蒙版图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
b_nand
image.b_nand(image[,mask = None]) 与另外图像做取反后做逻辑与操作。 image: 另外一个需要操作的图像。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
b_or
image.b_or(image[,mask = None]) 另一个图像做逻辑或操作。 image: 另外一个需要操作的图像。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
b_nor
image.b_nor(image[,mask = None]) 与另一个图像做取反和或操作。 image: 需要操作的图像。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
b_xor
image.b_xor(image[,mask = None]) 与另一个图像做异或操作。 image: 另外一个进行操作的图像。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
b_xnor
image.b_xnor(image[,mask = None]) 另一个图像做取反异或操作。 image: 另外一个操作的图像。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
erode
image.erode(size[,threshold[,mask = None]]) 对图像做腐蚀操作。 size: 滤波器大小,此方法的工作原理是将 ((size*2)+1)x((size*2)+1) 像素的内核卷积到图像上,如果相邻像素集集之和不大于threshold,则将内核的中心像素归零。 threshold: 如果未设置阈值,则此方法的工作方式类似于标准侵蚀方法。如果设置了 ,则可以指定侵蚀为仅侵蚀像素,例如,在其周围设置小于 2 像素且阈值为 2 的像素。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
dilate
image.dilate(size[,threshold,[mask = None]]) 对图像做膨胀操作。 size: 滤波器的大小,此方法的工作原理是将 ((size*2)+1)x((size*2)+1) 像素的内核卷积到图像上,如果相邻像素集的总和大于 ,则设置内核的中心像素。 threshold: 如果未设置阈值,则此方法的工作方式类似于标准扩张方法。如果设置了 ,则可以将“扩张”指定为仅扩张像素,例如,围绕这些像素设置的像素超过 2,阈值为 2。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
open
image.open(size[,threshold[,mask = None]]) 按顺序对图像执行侵蚀和膨胀。 mask: 素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
close
image.close(size[,threshold[,mask = None]]) 按顺序对图像执行膨胀和侵蚀。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
top_hat
image.top_hat(size[,threshold[,mask = None]]) 返回图像和 image.open 图像的图像差异。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。
black_hat
image.black_hat(size[,threshold,mask = None]]) 返回图像和 image.close 图像的图像差异。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。
gamma_corr
image.gamma_corr([gamma=1.0,[contrast=1.0,[brightness=0.0]) 快速更改图像灰度系数、对比度和亮度。请使用此方法代替image.mul 或 image.div,它们用于混合以调整像素值。 gamma值大于 1.0 会使图像以非线性方式变暗,而小于 1.0 会使图像更亮。通过将所有像素color通道缩放到 [0:1) 之间,然后在缩小之前对所有像素进行重新映射,将 gamma 值应用于图像。pow(pixel, 1/gamma) contrast值大于 1.0 会使图像以线性方式变亮,而小于 1.0 会使图像变暗。通过将所有像素color通道缩放到 [0:1) 之间,然后在缩小之前对所有像素进行重新映射,将对比度值应用于图像。pixel * contrast brightness值大于 0.0 会使图像以恒定的方式变亮,而小于 0.0 会使图像变暗。通过将所有像素color通道缩放到 [0:1) 之间,然后在缩小之前对所有像素进行重新映射,将亮度值应用于图像。pixel + brightness 返回图像对象。
negate
image.negate() 数字反转图像中的所有像素值。例如,对于灰度图像,此方法将所有像素从 更改为 。pixel255 - pixel 返回图像对象。
replace
image.replace(image[, hmirror=False[, vflip=False[, transpose=False[, mask=None]]]]) 将图像对象中的所有像素替换为新图像。 image: 可以是另一个图像对象、未压缩图像文件的路径(bmp/pgm/ppm)或标量值。如果是标量值,则该值可以是 RGB888 元组或基础像素值(例如,灰度图像为 8 位灰度,RGB 图像为 RGB565 值)。 hmirror: 设置为 True 可水平镜像替换图像。 vflip: 设置为 True 可垂直翻转替换图像。 transpose: 设置为 True 可沿对角线翻转图像(如果图像不是正方形,则会更改图像的宽度/高度)。 如果要将图像旋转 90 度的倍数,请执行以下操作: vflip=False, hmirror=False, transpose=False -> 0 度旋转 vflip=True, hmirror=False, transpose=True -> 90 度旋转 vflip=True, hmirror=True, 转置=False -> 180 度旋转 vflip=False, hmirror=True, transpose=True -> 270 度旋转 注意 如果不传递,此方法将对要替换的基础映像进行操作,方法是应用 、 和 选项来旋转图像。例如,如果你想做,你只需要做。imagehmirrorvfliptransposeimg.replace(img, etc...)img.replace(etc..) mask是另一个用作操作的像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。请注意,蒙版是在 hmirror/vflip/转置之前应用于图像的,因此蒙版的宽度/高度应与初始未修改图像的宽度/高度相同。 返回图像对象。
assign
image.assign(image, hmirror=False, vflip=False, transpose=False, mask=None[[[[]]]]) image.replace 的别名。
set
image.set(image, hmirror=False, vflip=False, transpose=False, mask=None[[[[]]]]) image.replace 的别名。
add
image.add(image[,maske = None[]) 将图像像素添加到此图像中。 image: 可以是图像对象、未压缩图像文件的路径(bmp/pgm/ppm)或标量值。如果是标量值,则该值可以是 RGB888 元组或基础像素值(例如,灰度图像为 8 位灰度,RGB 图像为 RGB565 值)。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
sub
image.sub(image[,invert=False[,maske=None]]) 将图像像素逐像素减去。 image: 可以是图像对象、未压缩图像文件的路径(bmp/pgm/ppm)或标量值。如果是标量值,则该值可以是 RGB888 元组或基础像素值(例如,灰度图像为 8 位灰度,RGB 图像为 RGB565 值)。 invert: 设置为 True 可将减法运算从 反转为 。reversethis_image-imageimage-this_image mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
mul
image.mul(image[,invert=False[,mask=None]]) 将两个图像按像素相乘。 image: 可以是图像对象、未压缩图像文件的路径(bmp/pgm/ppm)或标量值。如果是标量值,则该值可以是 RGB888 元组或基础像素值(例如,灰度图像为 8 位灰度,RGB 图像为 RGB565 值)。 invert: 设置为 True 可将乘法运算从 更改为 。特别是,这可以使图像变亮而不是变暗(例如,乘法与刻录操作)。inverta*b1/((1/a)*(1/b)) mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。 注意 此方法用于图像混合,不能将图像中的像素乘以标量,如需要乘以标量,需要使用image.gamma_corr。
div
image.div(image[,invert=False[,mod=False[,mask=None]]]) 将此图像除以另一个图像。 image: 可以是图像对象、未压缩图像文件的路径(bmp/pgm/ppm)或标量值。如果是标量值,则该值可以是 RGB888 元组或基础像素值(例如,灰度图像为 8 位灰度,RGB 图像为 RGB565 值)。 invert: 设置为 True 可将除法方向从 更改为 。 mod: 设置为 True 可将除法运算更改为模运算。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。 注意 此方法用于图像混合,不能将图像中的像素乘以标量,如需要乘以标量,需要使用image.gamma_corr。
min
image.min(image[,mask = None]) 按像素返回两个图像的最小图像。 image: 可以是图像对象、未压缩图像文件的路径(bmp/pgm/ppm)或标量值。如果是标量值,则该值可以是 RGB888 元组或基础像素值(例如,灰度图像为 8 位灰度,RGB 图像为 RGB565 值)。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
max
image.max(image[,mask = None]) 按像素返回两个图像的最大图像。 image: 可以是图像对象、未压缩图像文件的路径(bmp/pgm/ppm)或标量值。如果是标量值,则该值可以是 RGB888 元组或基础像素值(例如,灰度图像为 8 位灰度,RGB 图像为 RGB565 值)。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
difference
image.difference(image[,mask = None]) 返回两个图像之间的绝对差分图像(例如||a-b||)。 image: 可以是图像对象、未压缩图像文件的路径(bmp/pgm/ppm)或标量值。如果是标量值,则该值可以是 RGB888 元组或基础像素值(例如,灰度图像为 8 位灰度,RGB 图像为 RGB565 值)。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
blend
image.blend(image[,alpha=128[,mask=None]]) Alpha 将两个图像相互混合。 image: 可以是图像对象、未压缩图像文件的路径(bmp/pgm/ppm)或标量值。如果是标量值,则该值可以是 RGB888 元组或基础像素值(例如,灰度图像为 8 位灰度,RGB 图像为 RGB565 值)。 alpha: 控制要将其他图像的多少内容混合到此图像中。 应为介于 0 和 256 之间的整数值。接近零的值会将更多其他图像混合到此图像中,而接近 256 的值则相反。alpha mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
histeq
image.histeq([adaptive =False[,clip_limit=-1[,mask =None]]]) 对图像运行直方图均衡算法。直方图均衡可归一化图像中的对比度和亮度。 adaptive: 为 True,则将在图像上运行自适应直方图均衡方法,该方法通常比非自适应直方图限定结果更好,但运行时间更长。 clip_limit: 提供了一种限制自适应直方图限定的对比度的方法。为此使用一个小值(如 10),以生成良好的直方图均衡对比度有限图像。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
mean
image.mean(size, [threshold=False, [offset=0, [invert=False, [mask=None]]]]]) 使用滤波器进行标准均值模糊。 size: 是内核大小。使用 1(3x3 内核)、2(5x5 内核)等。 threshold: 在滤波器的输出上使用自适应阈值,可以通过该阈值来启用图像的自适应阈值,该阈值将根据像素的亮度相对于周围像素内核的亮度将像素设置为1或零。负值将更多的像素设置为 1,因为您使该像素更加负值,而正值仅将最锐利的对比度变化设置为 1。设置为反转生成的二进制图像输出。threshold=Trueoffsetinvert mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
median
image.median(size[,perecentile = 0.5[,threshold = False[,offset = 0[,invert = False[,mask = None]]]]]) 对图像运行中值滤波器。中值滤波器是平滑表面同时保留边缘的最佳滤波器。 size: 是内核大小。使用 1(3x3 内核)、2(5x5 内核)等。 percentile: 控制内核中使用的值的百分位数。默认情况下,每个像素都替换为其相邻像素的第 50 个百分位(中心)。对于最小筛选器,可以将其设置为 0,对于下四分位数筛选器,可以将其设置为 0.25,对于上四分位数筛选器,可以将其设置为 0.75,对于最大筛选器,可以将其设置为 1.0。 threshold: 在滤波器的输出上使用自适应阈值,可以通过该阈值来启用图像的自适应阈值,该阈值将根据像素的亮度相对于周围像素内核的亮度将像素设置为1或零。负值将更多的像素设置为 1,因为您使该像素更加负值,而正值仅将最锐利的对比度变化设置为 1。设置为反转生成的二进制图像输出。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
mode
image.mode(size[, threshold=False[,offset=0[,invert=False[, maske=None]]]]]) 通过将每个像素替换为其相邻像素的模式,对图像运行模式滤波。此方法在灰度图像上效果很好。然而,在RGB图像上,由于操作的非线性性质,它会在边缘上产生很多伪像。 size: 是内核大小。使用 1(3x3 内核)、2(5x5 内核)等。 threshold: 在过滤器的输出上使用自适应阈值,可以通过该阈值来启用图像的自适应阈值,该阈值将根据像素的亮度相对于周围像素内核的亮度将像素设置为1或零。负值将更多的像素设置为 1,因为您使该像素更加负值,而正值仅将最锐利的对比度变化设置为 1。设置为反转生成的二进制图像输出。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
midpoint
image.midpoint(size[,bias =0.5[,threshold=False[,offset=0[,invert=False[,mask=None]]]]]) 对图像运行中点滤镜。此滤镜查找图像中每个像素邻域的中点 ((最大值-最小值)/2)。 size: 是内核大小。使用 1(3x3 内核)、2(5x5 内核)等。 bias: 控制最小/最大混合。0 仅用于最小滤波,1.0 仅用于最大滤波。通过使用,您可以最小化/最大过滤图像。 threshold: 在滤波器的输出上使用自适应阈值,可以通过该阈值来启用图像的自适应阈值,该阈值将根据像素的亮度相对于周围像素内核的亮度将像素设置为1或零。负值将更多的像素设置为 1,因为您使该像素更加负值,而正值仅将最锐利的对比度变化设置为 1。设置为反转生成的二进制图像输出。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
morph
image.morph(size, kernel[, mul[, add=0[, threshold=False[, offset=0[, invert=False[, mask=None]]]]]]) 通过过滤器内核对图像进行卷积。这允许您对图像进行通用卷积。 size: 控制内核的大小,该内核必须是 ((size*2)+1)x((size*2)+1) 元素。 kernel: 是卷积图像的内核。它可以是元组或整数值列表。 mul: 是将卷积像素结果乘以的数字。如果未设置,则默认为一个值,该值将阻止卷积输出中的缩放。 add: 是要添加到每个卷积像素结果的值。 mul: 基本上允许您进行全局对比度调整,并允许您进行全局亮度调整。超出图像最小值和color通道最大值的像素将被剪切。add threshold: 在滤波器的输出上使用自适应阈值,可以通过该阈值来启用图像的自适应阈值,该阈值将根据像素的亮度相对于周围像素内核的亮度将像素设置为1或零。负值将更多的像素设置为 1,因为您使该像素更加负值,而正值仅将最锐利的对比度变化设置为 1。 invert: 设置为反转生成的二进制图像输出。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
gaussian
image.gaussian(size[, unsharp=False[, mul[, add=0[, threshold=False[, offset=0[, invert=False[, mask=None]]]]]]]) 通过平滑的瓜西核对图像进行卷积。 size: 是内核大小。使用 1(3x3 内核)、2(5x5 内核)等。 unsharp: 如果设置为 True,则此方法将执行不清晰的蒙版操作,而不是仅执行鸟祇滤波操作,从而提高边缘的图像清晰度。unsharp mul 是将卷积像素结果乘以的数字。如果未设置,则默认为一个值,该值将阻止卷积输出中的缩放。 add: 是要添加到每个卷积像素结果的值。 mul: 基本上允许您进行全局对比度调整,并允许您进行全局亮度调整。超出图像最小值和color通道最大值的像素将被剪切。add threshold: 在滤波器的输出上使用自适应阈值,则可以通过该阈值来启用图像的自适应阈值,该阈值将根据像素的亮度相对于周围像素内核的亮度将像素设置为1或零。负值将更多的像素设置为 1,因为您使该像素更加负值,而正值仅将最锐利的对比度变化设置为 1。 invert: 设置为反转生成的二进制图像输出。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
laplacian
image.laplacian(size[,sharpen=False[,mul[,add=0[,threshold=False[,offset=0[,invett=False[,mask=None]]]]]]]) 通过边缘检测拉普拉斯核对图像进行卷积。 size: 是内核大小。使用 1(3x3 内核)、2(5x5 内核)等。 sharpen: 如果设置为 True,则此方法将反而锐化图像,而不是仅输出非阈值边缘检测图像。然后增加内核大小以增加图像清晰度。 mul: 是将卷积像素结果乘以的数字。如果未设置,则默认为一个值,该值将阻止卷积输出中的缩放。 add: 是要添加到每个卷积像素结果的值。 mul: 基本上允许您进行全局对比度调整,并允许您进行全局亮度调整。超出图像最小值和color通道最大值的像素将被剪切。add threshold: 在滤波器的输出上使用自适应阈值,可以通过该阈值来启用图像的自适应阈值,该阈值将根据像素的亮度相对于周围像素内核的亮度将像素设置为1或零。负值将更多的像素设置为 1,因为您使该像素更加负值,而正值仅将最锐利的对比度变化设置为 1。 invert: 设置为True反转生成的二进制图像输出。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
bilateral
image.bilateral(size[, color_sigma=0.1[, space_sigma=1[, threshold=False[, offset=0[, invert=False[, maske=None]]]]]]) 通过双边滤镜对图像进行卷积。双边滤镜平滑图像,同时保持图像中的边缘。 size: 是内核大小。使用 1(3x3 内核)、2(5x5 内核)等。 color_sigma: 控制使用双边滤镜匹配color的紧密程度。增加此值可增加color模糊。 space_sigma: 控制像素在空间上彼此模糊的紧密程度。增加此值可增加像素模糊。 threshold: 在滤波器的输出上使用自适应阈值,则可以通过该阈值来启用图像的自适应阈值,该阈值将根据像素的亮度相对于周围像素内核的亮度将像素设置为1或零。负值将更多的像素设置为 1,因为您使该像素更加负值,而正值仅将最锐利的对比度变化设置为 1。 invert: 设置为True反转生成的二进制图像输出。 mask: 像素级蒙版的图像。蒙版应为仅具有黑色或白色像素的图像,并且应与正在操作的图像大小相同。仅修改蒙版中设置的像素。 返回图像对象。
linpolar
image.linpolar([invert = False]) 将图像从笛卡尔坐标重新投影到线性极坐标。 reverse: 设置为True以相反方向重新投影。 线性极性重投影将图像的旋转转换为 x 平移。
logpolar
image.logpolar([invert = False]) 从笛卡尔坐标重新投影和图像以记录极坐标。 reverse: 设置为True以相反方向重新投影。 对数极坐标重新投影将图像的旋转转换为 x 平移,缩放/缩放为 y 平移。
lens_corr
image.lens_corr([strength=1.8[,scale=1.0[,x_corr=0.0[,y_corr=0.0]]]]) 执行镜头校正以取消鱼眼图像,因为镜头失真。 strength: 是一个浮标,定义了取消鱼眼图像的量。默认情况下尝试1.8 out,然后从那里增加或减少,直到图像看起来不错。 zoom: 是放大图像的量。默认为 1.0。 x_corr: 从中心偏移的浮点像素。可以是负数,也可以是阳性。 y_corr: 从中心偏移的浮点像素。可以是负数,也可以是阳性。 返回图像对象。
rotation_corr
image.rotation_corr([x_rotation=0.0[, y_rotation=0.0[, z_rotation=0.0[, x_translation=0.0[, y_translation=0.0[, scale=1.0[, fov=60.0[, angle]]]]]]]]) 通过对帧缓冲区执行 3D 旋转来更正图像中的透视问题。 x_rotation: 是帧缓冲区中图像绕 x 轴旋转的度数(即,这会上下旋转图像)。 y_rotation: 是帧缓冲区中图像围绕 y 轴旋转的度数(即,这会左右旋转图像)。 z_rotation: 是帧缓冲区中图像围绕 z 轴旋转的度数(即,这会将图像旋转到位)。 x_translation: 是旋转后将图像向左或向右移动的单位数。由于此平移应用于3D空间,因此单位不是像素... y_translation: 是旋转后将图像向上或向下移动的单位数。由于此平移应用于3D空间,因此单位不是像素... zoom是放大图像的量。默认为 1.0。 fov: 是在 3D 空间中旋转图像之前执行 2D-> 3D 投影时要在内部使用的视场。当此值接近 0 时,图像放置在远离视口的无穷远处。当此值接近 180 时,图像将放置在视口中。通常,不应更改此值,但可以对其进行修改以更改 2D->3D 映射效果。 corners: 是四个 (x,y) 元组的列表,这些元组表示四个角,用于创建 4 点对应同调,该同形将第一个角映射到 (0, 0),将第二个角映射到 (image_width-1, 0),将第三个角映射到 (image_width-1, image_height-1),将第四个角映射到 (0, image_height-1)。然后,在重新映射图像后应用 3D 旋转。此参数允许您使用rotation_corr来执行鸟瞰图转换等操作。例如: top_tilt = 10 # if the difference between top/bottom_tilt become to large this method will stop working bottom_tilt = 0 points = [(tilt, 0), (img.width()-tilt, 0), (img.width()-1-bottom_tilt, img.height()-1), (bottom_tilt, img.height()-1)] img.rotation_corr(corners=points) 返回图像对象。
get_histogram
image.get_histogram([threshold[,invert = False[,roi,hist[,l_bins,a_bins,b_bins,difference]]]]]]]]) 计算所有color通道上的归一化直方图,并返回 image.直方图对象。有关详细信息,请参阅 image.histogram 对象。也可以使用 roiimage.get_hist()或image.histogram()调用此方法。 thresholds: 如果传递列表,则直方图信息将仅根据阈值列表中的像素计算。 thresholds必须是定义要跟踪的color范围的元组列表。对于灰度图像,每个元组需要包含两个值 - 最小灰度值和最大灰度值。将仅考虑介于这些阈值之间的像素区域。对于 RGB565 图像,每个元组需要有六个值(l_lo、l_hi、a_lo、a_hi、b_lo、b_hi) - 分别是 LAB L、A 和 B 通道的最小值和最大值。为了便于使用,此功能将自动修复交换的最小值和最大值。此外,如果元组大于六个值,则忽略其余部分。相反,如果元组太短,则False定其余阈值处于最大范围。[(lo, hi), (lo, hi), ..., (lo, hi)] [CAUTION] 要获取要跟踪的对象的阈值,只需在 IDE 帧缓冲区中选择要跟踪的对象上选择(单击并拖动)即可。然后,直方图将更新为仅位于该区域中。然后只需记下color分布在每个直方图通道中开始和下降的位置。这些将是 您的低值和高值。最好手动确定阈值,而不是使用上限和下四分位数统计信息,因为它们太紧了。 您还可以通过在IDE中使用阈值分析工具,来确定color阈值。工具->阈值分析工具 invert: 反转阈值操作,以便匹配某些已知color边界内的像素,而不是匹配已知color边界之外的像素。 除非您需要使用color统计信息执行高级操作,否则只需使用 image.get_statistics() 方法而不是此方法来查看图像中的像素区域。 roi: 是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则使用整个图像。仅对roi中的像素进行操作。 bins 对于灰度图像,是用于直方图通道的条柱数。对于彩色图像,是每个通道使用的图像。每个通道的bins计数必须大于 2。此外,将bins计数设置为大于每个通道的唯一像素值数是没有意义的。默认情况下,historgram 将具有每个通道的最大条柱数。 difference: 可以设置为图像对象,以使该方法对当前图像和图像对象之间的差异图像进行操作。这样就不必使用单独的缓冲区。
get_statistics
image.get_statistics([threshold[,invert = False[,roi[,bins[,l_bins[,a_bins[,b_bins[,difference]]]]]]]]) 计算图像所有color通道的平均值、中位数、模式、标准差、最小值、最大值、下四分位数和上限四分位数,并返回 image.statistics 对象。 有关详细信息,请参阅image.statistics 对象。 也可以使用roiimage.get_stats 或 image.statisticsthresholds调用此方法。如果传递列表,则直方图信息将仅根据阈值列表中的像素计算。 thresholds: 是定义跟踪的color范围的元组列表。对于灰度图像,每个元组需要包含两个值 - 最小灰度值和最大灰度值。将仅考虑介于这些阈值之间的像素区域。对于彩色图像,每个元组需要有六个值(l_lo、l_hi、a_lo、a_hi、b_lo、b_hi) - 分别是 LAB L、A 和 B 通道的最小值和最大值。为了便于使用,此功能将自动修复交换的最小值和最大值。此外,如果元组大于六个值,则忽略其余部分。相反,如果元组太短,则使阈值处于最大范围。[(lo, hi), (lo, hi), ..., (lo, hi)] 注意 invert: 反转阈值操作,以便匹配某些已知color边界内的像素,而不是匹配已知color边界之外的像素。 每当需要获取有关图像中像素区域值的信息时,您都需要使用此方法。例如,如果您尝试使用帧差异检测运动,则需要使用此方法确定图像color通道的变化以触发运动检测阈值。 roi: 是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对roi中的像素进行操作。 bins: 其他是用于直方图通道的条柱数。对于灰度图像,请使用RGB565图像,每个通道使用其他图像。每个通道的箱计数必须大于 2。此外,将箱计数设置为大于每个通道的唯一像素值数是没有意义的。默认情况下,historgram 将具有每个通道的最大条柱数。bins difference: 可以设置为图像对象,以使该方法对当前图像和图像对象之间的差异图像进行操作。这样就不必使用单独的缓冲区。difference
get_regression
image.get_regression(threshold[,invert=False[,roi[,x_stride=2[,y_stride=1[,area_threshold=10[,pixels_threshold=10[,robust=False]]]]]]]) 计算图像中所有阈值像素的线性回归。线性回归通常使用最小二乘法计算,最小二乘法速度很快,但无法处理任何异常值。如果为 True,则使用 Theil–Sen 线性回归来计算图像中所有阈值像素之间所有斜率的中位数。这是一个 N^2 操作,如果在阈值后设置了太多像素,即使在 80x60 图像上,也可能使 FPS 降至 5 以下。但是,只要阈值后设置的像素数仍然很低,线性回归就有效,即使高达 30% 的阈值像素是异常值(例如,它是健壮的)。robust 此方法返回一个 image.line 对象。 thresholds: 必须是定义要跟踪的color范围的元组列表。对于灰度图像,每个元组需要包含两个值 - 最小灰度值和最大灰度值。将仅考虑介于这些阈值之间的像素区域。对于 RGB565 图像,每个元组需要有六个值(l_lo、l_hi、a_lo、a_hi、b_lo、b_hi) - 分别是 LAB L、A 和 B 通道的最小值和最大值。为了便于使用,此功能将自动修复交换的最小值和最大值。此外,如果元组大于六个值,则忽略其余部分。相反,如果元组太短,则False定其余阈值处于最大范围。[(lo, hi), (lo, hi), ..., (lo, hi)] 注意 invert: 反转阈值操作,以便匹配某些已知color边界内的像素,而不是匹配已知color边界之外的像素。 roi: 是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对 中的像素进行操作。roi x_stride: 是评估图像时要跳过的 x 像素数。 y_stride: 是评估图像时要跳过的 y 像素数。 如果回归的边界框面积小于,则返回 None。area_threshold 如果回归的像素计数小于,则返回 None。pixels_threshold
图像机器视觉分析函数
find_blobs
image.find_blobs(threshold[,invert=False[,roi[,x_stride=2[,y_stride=1[,area_threshold=10[,pixels_threshold=10[,merge=False[,=0[,threshold_cb=None[,merge_cb=None[,x_hist_bins_max=0[,y_hist_bins_max=0]]]]]]]]]]]]) 查找映像中的所有 blob(通过阈值测试的已连接像素区域),并返回描述每个 blob 的 image.blob 对象列表。有关详细信息,请参阅 image.blob 对象。 thresholds: 必须是定义要跟踪的color范围的元组列表。一次调用最多可以传递 32 个阈值元组。对于灰度图像,每个元组需要包含两个值 - 最小灰度值和最大灰度值。将仅考虑介于这些阈值之间的像素区域。对于 RGB565 图像,每个元组需要有六个值(l_lo、l_hi、a_lo、a_hi、b_lo、b_hi) - 分别是 LAB L、A 和 B 通道的最小值和最大值。为了便于使用,此功能将自动修复交换的最小值和最大值。此外,如果元组大于六个值,则忽略其余部分。相反,如果元组太短,则False定其余阈值处于最大范围。[(lo, hi), (lo, hi), ..., (lo, hi)] 注意 要获取要跟踪的对象的阈值,只需在 IDE 帧缓冲区中选择要跟踪的对象上选择(单击并拖动)即可。然后,直方图将更新为仅位于该区域中。然后只需记下color分布在每个直方图通道中开始和下降的位置。这些将是 您的低值和高值。最好手动确定阈值,而不是使用上限和下四分位数统计信息,因为它们太紧了。thresholds 您还可以通过在 ZNZPI IDE 中进入并从 GUI 滑块窗口中选择阈值来确定color阈值。工具->阈值分析 invert: 反转阈值操作,以便匹配某些已知color边界内的像素,而不是匹配已知color边界之外的像素。 roi: 是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对 中的像素进行操作。roi x_stride: 是搜索 blob 时要跳过的 x 像素数。找到斑点后,线条fill算法将像素精确。增加以加快查找 Blob(如果已知 Blob 很大)的速度。x_stride y_stride: 是搜索 Blob 时要跳过的 y 像素数。找到斑点后,线条fill算法将像素精确。增加以加快查找 Blob(如果已知 Blob 很大)的速度。y_stride 如果 Blob 的边界框区域小于筛选出的区域。area_threshold 如果 Blob 的像素数小于滤除的像素数。pixels_threshold merge: 如果为True,合并所有未筛选出的blob,则边界矩形的 blob 会相互相交。可用于在交集测试期间增加或减少 Blob 的边界矩形的大小。例如,如果边距为 1 个 Blob,则边界矩形彼此相距 1 像素的 Blob 将被合并。margin 通过合并 Blob,可以实现color代码跟踪。每个 Blob 对象都有一个值,该值是一个位向量,每个color阈值由 1 组成。例如,如果传递find_blobs image.find_blobs两个color阈值,则第一个阈值的代码为 1,第二个阈值的代码为 1(第三个阈值为 4,第四个阈值为 8,依此类推)。在逻辑上将 Blob 或所有代码合并在一起,以便您知道产生它们的color。这允许您跟踪两种color,如果您用两种color返回一个 blob 对象,那么您知道它可能是一个color代码。code 如果使用的是紧密的color边界,则可能还需要合并 Blob,这些color边界不能完全跟踪您尝试跟踪的对象的所有像素。 最后,如果要合并 blob,但是,不希望合并两个color阈值,则只需使用单独的阈值调用 find_blobs image.find_blobs两次,这样 blob 就不会合并。 threshold_cb可以设置为函数,以便在阈值化后调用每个 blob,以将其从要合并的 blob 列表中筛选出来。回调函数将接收一个参数 - 要筛选的 blob 对象。然后,回调必须返回 True 以保留 blob,并返回 False 以筛选它。 merge_cb可以设置为函数以调用即将合并的每两个 blob,以防止或允许合并。回调函数将接收两个参数 - 要合并的两个 blob 对象。然后,回调必须返回 True 以合并 Blob,或返回 False 以防止合并 Blob。 x_hist_bins_max如果设置为非零,则使用对象中所有列的x_histogram投影fill每个 Blob 对象中的直方图缓冲区。然后,此值设置该投影的条柱数。 y_hist_bins_max如果设置为非零,则使用对象中所有行的y_histogram投影fill每个 Blob 对象中的直方图缓冲区。然后,此值设置该投影的条柱数。
find_lines
image.find_lines([roi, x_stride=2[, y_stride=1[, 阈值=1000[, theta_margin=25[, rho_margin=25]]]]]]) 使用 hough 变换查找图像中的所有无限行。 line: image.line 对象的列表。 roi: 是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对 中的像素进行操作。roi x_stride: 是执行 hough 转换时要跳过的 x 像素数。仅当您要搜索的行又大又笨重时,才增加此值。 y_stride: 是执行 hough 变换时要跳过的 y 像素数。仅当您要搜索的行又大又笨重时,才增加此值。 threshold: 控制从 hough 变换中检测到哪些行。仅返回大小大于或等于 的线。对于您的应用程序而言,正确的值取决于映像。请注意,一条线的大小是构成该线的像素的所有 sobel 滤波器大小之和。thresholdthreshold theta_margin: 控制检测到的行的合并。相距数和相距数的线将合并。theta_marginrho_margin rho_margin: 控制检测到的行的合并。相距数和相距数的线将合并。theta_marginrho_margin 该方法的工作原理是在图像上运行sobel滤波器,并从sobel滤波器中获取幅度和梯度响应,以提供hough变换。它不需要首先对映像进行任何预处理。但是,我使用过滤清理图像,您可能会获得更稳定的结果。
find_line_segments
image.find_line_segments([roi[, merge_distance=0[, max_theta_difference=15]]]) 使用 hough 变换查找图像中的线段。返回 line:image.line 对象的列表。 roi: 是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对 中的像素进行操作。roi merge_distance: 指定要合并的两行分隔线(在一行上的任意点)可以相互分隔的最大像素数。 max_theta_difference: 是要合并的相距两条线相隔的度数的最大θ差。merge_distance 此方法使用 LSD 库(也由 OpenCV 使用)来查找图像中的行分隔。它有点慢,但非常准确,线条不会跳来跳去。
find_circles
image.find_circles([roi, x_stride=2[, y_stride=1[, threshold=2000[, x_margin=10[, y_margin=10[, r_margin=10[, r_min=2[, r_max[, r_step=2]]]]]]]]]]) 使用 hough 变换在图像中查找圆。返回 circle: image.circle 对象的列表。 roi: 是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对 中的像素进行操作。roi x_stride: 是执行 hough 转换时要跳过的 x 像素数。只有在您要搜索的圆圈又大又笨重时才增加此值。 y_stride: 是执行 hough 变换时要跳过的 y 像素数。只有在您要搜索的圆圈又大又笨重时才增加此值。 threshold: 控制从 hough 变换中检测到哪些圆。仅返回大小大于或等于 的圆。对于您的应用程序而言,正确的值取决于映像。请注意,圆的大小是组成该圆的像素的所有 sobel 滤波器大小之和。thresholdthreshold x_margin: 控制检测到的圆圈的合并。相距的圆 、和像素相距。x_marginy_marginr_margin y_margin: 控制检测到的圆圈的合并。相距的圆 、和像素相距。x_marginy_marginr_margin r_margin: 控制检测到的圆圈的合并。相距的圆 、和像素相距。x_marginy_marginr_margin r_min: 控制检测到的最小圆半径。增加此值可加快算法速度。默认值为 2。 r_max: 控制检测到的最大圆半径。减小此值可加快算法速度。默认值为 min(roi.w/2, roi.h/2)。 r_step: 控制如何步进半径检测。默认值为 2。
find_rects
image.find_rects([roi=auto[,threshold=10000]]) 使用与查找四边形标签相同的四边形检测算法查找图像中的矩形。最适合与背景形成良好对比度的矩形。四边形检测算法可以处理矩形上的任何缩放/旋转/剪切。 返回rect: image.rect 对象的列表。 roi: 是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对roi中的像素进行操作。 threshold: 边缘大小小于threshold 的矩形(通过在矩形边缘上的所有像素上滑动 sobel 运算符并对其值求和来计算),从返回的列表中过滤掉。
find_qrcodes
image.find_qrcodes([roi]) 查找roi中的所有 qrcode,并返回qrcode: image.qrcode 对象的列表。 QR码需要在图像中相对平坦,此方法才能正常工作。通过使用sensor.set_windowing() 函数放大镜头中心,image.lens_corr() 矫正镜头畸变,或者只是将镜头更换为视野较窄的物体,您可以获得不受镜头畸变影响的更平坦的图像。 roi是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对roi中的像素进行操作。
find_apriltags
image.find_apriltags([roi[,families=image.TAG36H11[, fx[, fy[, cx[, cy]]]]]]) 查找roi中的所有 apriltag,并返回image.apriltag 对象的列表。有关详细信息,请参阅 image.apriltag 对象。 与QR码不同,AprilTags可以在更远的距离,更差的照明,扭曲的图像等处检测到。AprilTags可以真好的处理各种图像失真问题,这QR码是无法做到的。也就是说,AprilTags只能将数字ID编码为其有效负载。 AprilTags 也可用于本地化目的。每个image.apriltag 对象从相机返回其平移和旋转。平移的单位由 fx 、fy 、cx 和 cy 分别是图像在 X 和 Y 方向上的焦距和中心点确定。 注意 要创建 AprilTags,请使用 IDE 中内置的标签生成器工具。标签生成器可以创建可打印的8.5“x11”标签。 roi是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对roi中的像素进行操作。 families: 是要解码的标记族的位掩码。它是以下各项的逻辑 OR: image.TAG16H5 image.TAG25H7 image.TAG25H9 image.TAG36H11 image.ARTOOLKIT 默认情况下,它只是图像。TAG36H11 这是最好的标签系列。请注意, image.find_apriltags() 会降低每个已启用标签系列的速度。 fx是相机 X 焦距(以像素为单位)。对于标准的znzp的M12镜头,这是(2.8 / 3.984)* 1920。这是镜头焦距(以毫米为单位),除以X方向上的相机传感器长度乘以X方向上的相机传感器像素数(对于GC2053相机)。 fx是相机 Y 焦距(以像素为单位)。对于标准的znzpi的M12镜头,这是(2.8 / 2.952)* 1080。这是以mm为单位的镜头焦距,除以Y方向上的相机传感器长度乘以Y方向上的相机传感器像素数(对于GC2053相机)。 cx是图像中心,它只是。这不是 。image.width()/2roi.w()/2 cy是图像中心,它只是。这不是 。image.height()/2roi.h()/2
find_datamatrices
image.find_datamatrices([roi[,effort= 200]]) 查找roi中的所有数据矩阵,并返回 image.datamatrix 对象的列表。有关详细信息,请参阅 image.datamatrix 对象。 数据矩阵需要在图像中相对平坦,此方法才能正常工作。通过使用sensor.set_windowing() 函数放大镜头中心,image.lens_corr() 镜头畸变矫正,或者只是将镜头更换为视野较窄的物体,您可以获得不受镜头畸变影响的更平坦的图像。有机器视觉镜头不会引起桶形失真,但它们比OpenMV提供的标准镜头贵得多。 roi: 是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对 中的像素进行操作。roi effort: 控制尝试查找数据矩阵匹配项所花费的时间。默认值 200 应该适用于所有用例。但是,您可以增加工作量,但要以帧速率为代价,才能提高检测率。您也可以降低提高帧速率的工作量,但是,以检测为代价...请注意,当 设置为低于 160 左右时,您将不再检测到任何内容。还要注意,您可以随心所欲地制作高。但是,任何高于240左右的值都不会导致检测率的大幅提高。efforteffort
find_barcodes
image.find_barcodes([roi]) 查找roi中的所有一维条形码,并返回 image.barcode 对象的列表。 为获得最佳效果,请使用 640 x 40/80/160 窗口。垂直分辨率越低,一切都运行得越快。由于条形码是线性一维图像,因此您只需要在一个方向上获得很大的分辨率,而在另一个方向上只需要一点分辨率。请注意,此功能可水平和垂直扫描,因此您可以根据需要使用 40/80/160 x 480 窗口。最后,确保调整镜头,以便条形码位于焦距产生最清晰图像的位置。模糊的条形码无法解码。 此功能支持所有这些一维条形码(基本上所有条形码): image.EAN2 image.EAN5 image.EAN8 image.UPCE image.ISBN10 image.UPCA image.EAN13 image.ISBN13 image.I25 image.DATABAR (RSS-14) image.DATABAR_EXP (RSS-Expanded) image.CODABAR image.CODE39 image.PDF417 image.CODE93 image.CODE128 roi是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对 中的像素进行操作。roi
find_displacement
image.find_displacement(template[, roi[, template_roi[, logpolar=False]]]) 从模板中查找此图像的平移偏移量。这种方法可以用来做光流。此方法返回一个image.displacement 对象,其中包含使用相位相关性的位移计算结果。 roi是要在其中工作的感兴趣区域矩形 (x, y, w, h)。如果未指定,则等于图像矩形。 template_roi是要在其中工作的感兴趣区域矩形 (x, y, w, h)。如果未指定,则等于图像矩形。 roi和 roi 必须具有相同的 w/h,但在图像中可以具有任何 x/y 位置。您可以在较大的图像周围滑动较小的rois以获得光流梯度图像...template
find_displacement
image.find_displacement() 通常计算两个图像之间的 x/y 平移。但是,如果您通过它,它将发现两个图像之间的旋转和缩放更改。相同的 image.displacement 对象结果对两种可能的回复进行编码。logpolar=True 注意 请在 2 的幂图像尺寸(例如传感器.B64X64)。
find_template
image.find_template(template,threshold[,roi[,step= 2[,search= image.SEARCH_EX]]]) 尝试使用归一化互相关查找图像中模板匹配的第一个位置。返回匹配位置的边界框元组 (x, y, w, h),否则返回 None。 template是与此图像对象匹配的小图像对象。请注意,两个图像都必须是灰度的。 threshold是浮点数 (0.0-1.0),其中较高的阈值可防止误报,同时降低检测率,而较低的阈值则相反。 roi是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对 中的像素进行操作。roi step是查找模板时要跳过的像素数。跳过像素大大加快了算法的速度。这只会影响SERACH_EX模式下的算法。 search可以是 或 。 使用比算法更快的算法搜索模板,但如果模板靠近图像边缘,则可能无法找到模板。 对图像进行详尽的搜索,但可能比 慢得多。image.SEARCH_DSimage.SEARCH_EX image.SEARCH_DSimage.SEARCH_EX image.SEARCH_EXimage.SEARCH_DS
find_features
image.find_features(级联,阈值 = 0.5,比例 = 1.5,roi[[[]]]) 此方法在图像中搜索与 Haar 级联中传递的区域匹配的所有区域,并返回围绕这些要素的边界框矩形元组 (x, y, w, h) 的列表。如果未找到任何要素,则返回空列表。 cascade是一个 Haar Cascade 对象。见图。HaarCascade() 了解更多详情。 threshold是一个阈值 (0.0-1.0),其中较小的值可提高检测率,同时提高误报率。相反,较高的值会降低检测率,同时降低误报率。 scale是必须大于 1.0 的浮点数。比例因子越高,运行速度越快,但图像匹配度越差。一个好的值介于 1.35 和 1.5 之间。 roi是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对 中的像素进行操作。roi
find_eye
image.find_eye(roi) 在眼睛周围的感兴趣区域(x,y,w,h)元组中搜索瞳孔。返回一个元组,其中包含图像中瞳孔的 (x, y) 位置。如果未找到瞳孔,则返回 (0,0)。 要使用这个函数,首先使用image.find_features()和HaarCascade来查找某人的脸。然后使用image.find_features()与HaarCascade一起使用来查找脸上的眼睛。最后,对image.find_features()返回的眼睛ROI调用此方法以获取瞳孔坐标。frontalfaceeye roi是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对 中的像素进行操作。roi 仅适用于灰度图像。
find_lbp
image.find_lbp(roi) 从感兴趣区域(x、y、w、h)元组中提取 LBP(局部二进制模式)关键点。然后,您可以使用然后使用image.match_descriptor()函数来比较两组关键点,以获得匹配的距离。 roi是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对 中的像素进行操作。 仅适用于灰度图像。
find_keypoints
image.find_keypoints([roi,阈值= 20,规范化= False,scale_factor = 1.5,max_keypoints = 100,corner_detector = 图像。CORNER_AGAST[[[[[]]]]]]) 从感兴趣区域 (x, y, w, h) 元组中提取 ORB 关键点。然后,您可以使用然后使用 image.match_descriptor()函数来比较两组关键点,以获得匹配的区域。如果未找到任何关键点,则返回 None。 roi: 是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对 中的像素进行操作。 threshold: 是一个数字(介于 0 - 255 之间),用于控制提取角的数量。对于默认的 AGAST 角探测器,此值应为 20 左右。FOr 快速角检测器,这应该在 60-80 左右。阈值越低,您获得的提取角就越多。 normalized: 是一个布尔值,如果 True 将关闭以多种分辨率提取关键点。如果您不关心处理缩放问题并希望算法运行得更快,请将此值设置为 true。 scale_factor: 是必须大于 1.0 的浮点数。比例因子越高,运行速度越快,但图像匹配度越差。一个好的值介于 1.35 和 1.5 之间。 max_keypoints: 是关键点对象可以持有的最大关键点数。如果关键点对象太大并导致 RAM 不足问题,则减小此值。 corner_detector: 是用于从图像中提取关键点的角检测器算法。它可以是任一图像。CORNER_FAST或图像。CORNER_AGAST。FAST角探测器速度更快,但精度要低得多。
find_edges
image.find_edges(edge_type[,threshold]) 将图像转换为黑白,仅留下边缘作为白色像素。 image.EDGE_SIMPLE - 简单的阈值高通滤波器算法。 image.EDGE_CANNY - Canny边缘检测算法。 threshold: 是包含低阈值和高阈值的双值元组。您可以通过调整这些值来控制边的质量。它默认为 (100, 200)。
find_hog([roi[,size = 8]])
将 ROI 中的像素替换为 HOG(定向粒度的直方图)线。 roi: 是感兴趣区域矩形元组 (x, y, w, h)。如果未指定,则等于图像矩形。仅对roi中的像素进行操作。
AI和神经网络
神经网络
通过load,导入ai模型。其中的参数为cnn模型数据路径。如果有TF卡,默认从TF卡中读取。 其次从userdata目录下读取,再次从flash中读取,系统内置的模型数据。 如果使用的是模型的文件名,需要使用完整的路径,模型放置mtp的U盘使用的路径为: /userdata/module 如果放置tf卡中,路径为 /mnt/sdcard/module/
关于模型的训练部分,请参考AI模型训练章节。
如果导入模型数据错误,返回none空数据,可以通过打印检查导入是否成功。
import image
import sensor
import ai
sensor.reset()
#load module , 80 objects
ml = ai.load('yolov5s_object.rknn',80)
#print(ml)
#img = sensor.snapshot()
#img = image.Image('cat_224x224.jpg')
#img = image.Image('dog_224x224.jpg')
def loop():
img = sensor.snapshot()
out = ml.forward(img)
print(out)
load
导入ai模型
ai.load(path) path:模型所在的路径,默认导入的次序为:1 TF卡 2 MTP的userdata 3 flash。 如果使用的是cnn模型的路径,则会导入其数据并建立模型。 如果使用的是如下预制的模型,则导入预制模型。 FACE_DETECTION = 1, #人脸检测 FACE_LANDMARK_68 = 2, #人脸68特征点定位 FACE_RECOGNIZE = 3, #人脸识别 FACE_ANALYZE = 4, #人脸分析 OBJECT_DETECTION = 5, #目标检测 POSE_BODY = 6, #身体骨骼关键点定位 POSE_FINGER_21 = 7, #手指21关键点定位 FACE_LANDMARK_5 = 8, #人脸5特征点定位 HEAD_DETECTION = 9, #人头检测 CARPLATE_DETECTION = 10, #车牌检测 CARPLATE_ALIGN = 11, #车牌矫正对齐 CARPLATE_RECOG = 12, #车牌识别 OBJECT_TRACK = 13, #目标跟踪 POSE_FINGER_3 = 14, #手指3点定位 FACE_LIVENESS = 15 #人脸活体检测,暂不支持 FACE_COMPARE #人脸特征对比
人脸检测的使用如下:
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.FACE_DETECT)
print(ml)
img = image.Image('face.jpg')
roi = (0,0,612,344)
def loop():
#img = sensor.snapshot()
print(img)
img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
for it in out:
print(it.rect())
img.draw_rectangle(it.rect(),color=(255,0,0), thickness=4)
save
保存ai模型,此函数未实现。
forward
进行ai推导计算
ai.forward(img,roi)
img: 需要进行计算的图像,可以由image.Image(path)导入的jpg图片,也可以是sensor.snapshot()得到的实时图像
图像的大小必须是和模型训练时一样尺寸。
roi: 需要处理的感兴趣区域
如果在load中使用的是cnn的模型,则还需要调用ai.prob(),来对姐u共进行进一步处理,得到推理结果。
如果使用的是预制的模型,则会直接得到推理结果。结果的格式参考下面的各个检测的描述。
prob
获取计算结果的可能排序
ai.prob(res,cnt) res:forward 计算的结果 返回按概率由大到小的顺序的cnt个结果
人脸
人脸检测
返回检测到的人脸列表,在每个列表项目,是人脸的位置,一个object结构。 其他的检测如,目标检测,车牌检测,返回的都是这个object类型的数据。
int object.id() 目标分类 int cls_idx() 目标类索引 tupel rect() 目标位置,返回四个int值,分别是left,top,right,bottom float score() 目标分辨得分 int x() 目标位置的左上角x坐标 int y() 目标位置的左上角y坐标 int w() 目标的宽度 int h() 目标的高度 string name() 目标分类名称 分别是 "???", "person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "trafficlight", "firehydrant", "???", "stopsign", "parkingmeter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "???", "backpack", "umbrella", "???", "???", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sportsball", "kite", "baseballbat", "baseballglove", "skateboard", "surfboard", "tennisracket", "bottle", "???", "wineglass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hotdog", "pizza", "donut", "cake", "chair", "couch", "pottedplant", "bed", "???", "diningtable", "???", "???", "toilet", "???", "tv", "laptop", "mouse", "remote", "keyboard", "cellphone", "microwave", "oven", "toaster", "sink", "refrigerator", "???", "book", "clock", "vase", "scissors", "teddybear", "hairdrier", "toothbrush"
从实时图像中检测人脸
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.FACE_DETECT)
print(ml)
roi = (620,220,640,640)
def loop():
img = sensor.snapshot() #获取实时图像
#print(img)
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
for it in out:
print(it.rect())
img.draw_rectangle(it.rect(),color=(255,0,0), thickness=4)
从图片中检测人脸
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.FACE_DETECT)
print(ml)
img = image.Image('face.jpg') #读取图片
roi = (0,0,612,344)
def loop():
img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
for it in out:
print(it.rect())
img.draw_rectangle(it.rect(),color=(255,0,0), thickness=4)
人脸识别
在load的时候使用FACE_RECONG。调用forward函数后,得到人脸特征。 返回一个类型为float的元组,可用于进行特征对比。
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.FACE_RECONG)
print(ml)
img = image.Image('face.jpg')
#roi = (820,320,640,640)
roi = (0,0,612,344)
def loop():
#img = sensor.snapshot()
print(img)
img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
for it in out:
print(it)
人脸特征
在load的时候使用FACE_ANALYZE。调用forward函数后,得到人脸特征。 返回一个类型为int的元组,为grender和age。
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.FACE_ANALYZE)
print(ml)
img = image.Image('face.jpg')
#roi = (820,320,640,640)
roi = (0,0,612,344)
def loop():
#img = sensor.snapshot()
print(img)
img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
print(out)
人脸特征比较
在load的时候使用FACE_COMPARE。调用forward函数后,得到人脸特征对比结果。 返回一个类型为float,来表示相似度。
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.FACE_RECONG)
fc = ai.load(ai.FACE_COMPARE)
print(ml)
img_a = image.Image('face_a.jpg')
img_b = image.Image('face_b.jpg')
#roi = (820,320,640,640)
roi = (0,0,612,344)
def loop():
#img = sensor.snapshot()
img_a.draw_image(img,(0,0))
img_b.draw_rectangle(roi, color=(255,0,0), thickness=4)
out_a = ml.forward(img_a,roi=roi)
out_b = ml.forward(img_b,roi=roi)
out = fc.forward(out_a,out_b)
print(out)
人脸姿态
使用ai.FACE_LAND68 作为ai.load()的参数。
返回一个代表面部姿态位置的face类型的数据。 其有如下的部分组成: int face.width() 面部图像的宽度 int face.height() 面部图像的高度 int face.rect() 面部的位置 int face.x() 面部的左上角x坐标 int face.y() 面部的左上角y坐标 int face.w() 面部的宽度 int face.h() 面部的高度 int face.count() 面部坐标的数量 tuple face.landmarks() 面部坐标(x,y)的元组 float face.pose() 面部的姿态,一个浮点数 float face.score() 面部检测的得分,一个浮点数 image face.image() 面部区域图像,此函数只有在使用ai.FACE_LAND5才有,使用ai.FACE_LAND68返回空值 如果forward()失败,则识别返回一个空值。
程序示例如下
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.FACE_LANDMARK_68)
print(ml)
img = image.Image('face_a.jpg')
#roi = (820,320,640,640)
roi = (0,0,612,344)
def loop():
#img = sensor.snapshot()
img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
ou = ml.forward(img,roi=roi)
print(out)
if out :
img.draw_image(out.image(),(200,200))
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.FACE_LAND68)
print(ml)
img = sensor.snapshot()
roi = (720,320,740,640)
def loop():
img = sensor.snapshot()
#img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
if out :
print(out.count())
print(out)
print(out.rect())
#for it in out.landmarks():
# img.draw_circle((it[0],it[1],10), color=(255,0,0), thickness=4)
物体检测和跟踪
物体检测使用ai.OBJECT_DETECT,物体跟踪使用ai.OBJECT_TRACK
物体检测的返回值中name是检测到的物体类型。物体检测的返回值,可以作为物体跟踪的输入。
object
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.OBJECT_DETECT)
print(ml)
img = image.Image('cat.jpg')
print(img)
img.draw_image(img,(0,0))
#roi = (820,320,640,640)
roi = (0,0,612,344)
def loop():
#img = sensor.snapshot()
img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
for it in out:
print(it.rect())
img.draw_rectangle(it.rect(),color=(255,0,0), thickness=4)
print(it.name())
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.OBJECT_DETECT)
tk = ai.load(ai.OBJECT_TRACK)
print(ml)
img = sensor.snapshot()
print(img)
roi = (720,320,740,640)
def loop():
img = sensor.snapshot()
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
print(out)
for it in out:
tout = tk.forward(img,roi=it.rect())
if tout :
print(tout)
车牌识别
车牌识别可以分为三部分,车牌检测,车牌矫正,车牌识别。 下面是是车牌识别示例。
import image
import sensor
import ai
sensor.reset()
cd = ai.load(ai.CARPLATE_DETECTION)
ca = ai.load(ai.CARPLATE_ALIGN)
cr = ai.load(ai.CARPLATE_RECONG)
print(ml)
img = image.Image('car.jpg')
print(img)
img.draw_image(img,(0,0))
#roi = (820,320,640,640)
roi = (0,0,612,344)
def loop():
#img = sensor.snapshot()
img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = cd.forward(img,roi=roi)
for it in out:
print(it.rect())
img.draw_rectangle(it.rect(),color=(255,0,0), thickness=4)
cimg = ca.forward(img,it.rect())
if cimg :
carlate = cr.forward(cimg,it.rect())
print(carplate)
车牌检测
在load的时候使用CARPLATE_DETECTION,调用forward函数后,返回车牌所在的区域信息列表。 调用rect()函数,得到区域的坐标,可以作为后续操作输入的roi。
车牌矫正
在load的时候使用CARPLATE_ALIGN,调用forward函数后,返回经过矫正包含车牌图像。可以作为识别的图像输入。
load(ai.CARPLATE_ALIGN)
车牌识别
在load的时候使用CARPLATE_RECONG。调用forward函数后,得到车牌的字符串。
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.CARPLATE_RECOG)
img = sensor.snapshot()
#img = image.Image('face.jpg')
print(img)
print(ml)
#img.draw_image(img,(0,0))
roi = (720,320,740,640)
#roi = (0,0,612,340)
def loop():
img = sensor.snapshot()
#img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
print(out)
姿态检测
手势
使用ai.POSE_FINGER 或ai.POSE_FINGER3 作为ai.load()的参数,分别获得21点和3点的手势。返回一个代表手势位置的坐标元组。 x,y是整数。
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.POSE_FINGER)
print(ml)
img = sensor.snapshot()
roi = (720,320,740,640)
def loop():
img = sensor.snapshot()
#img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
print(out)
for it in out:
img.draw_circle((it[0],it[1],10), color=(255,0,0), thickness=4)
身体姿态
使用ai.POSE_BODY 作为ai.load()的参数。返回一个代表身体姿态位置的坐标(x,y)的元组。 x,y是整数。
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.POSE_BODY)
print(ml)
img = sensor.snapshot()
roi = (720,320,740,640)
def loop():
img = sensor.snapshot()
#img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
print(out)
for it in out:
img.draw_circle(it, color=(255,0,0), thickness=4)
脸部姿态
使用ai.FACE_LAND5 作为ai.load()的参数。返回一个带图像的face类型
程序示例如下:
import image
import sensor
import ai
sensor.reset()
ml = ai.load(ai.FACE_LAND5)
print(ml)
img = sensor.snapshot()
roi = (720,320,740,640)
def loop():
img = sensor.snapshot()
#img.draw_image(img,(0,0))
img.draw_rectangle(roi, color=(255,0,0), thickness=4)
out = ml.forward(img,roi=roi)
print(out)
for it in out.landmarks():
img.draw_circle((it[0],it[1],10), color=(255,0,0), thickness=4)
模型训练
请参考侦侦拍AI训练用户手册
外设控制
GPIO
GPIO是一个基本的输入输出设备。通过设置为输入或输出,来获取或设置IO的为高或低电压。作为模拟设备,可以用于数模或模数转换。
GPIO的基本用法如下,所有的GPIO通过 pyb.Pin.board.Name来定义。
x1_pin = pyb.Pin.board.P1
g = pyb.Pin(pyb.Pin.board.P1, pyb.Pin.IN)
也可以使用,GPIO的以开发板管脚编号命名的名称和以别名命名的名称,其均可表示同一个GPIO管脚
例如 pyb.Pin.board.P1 和 pyb.Pin.cpu.B1 表示同一个GPIO.
import image
import sensor
import pyb
sensor.reset()
roi = (0,0,600,600)
def loop():
p1 = pyb.Pin('P1', pyb.Pin.OUT_PP)
p1.high()
也可以使用用户自定义的名称
MyMapperDict = { 'LeftMotorDir' : pyb.Pin.cpu.A12 }
pyb.Pin.dict(MyMapperDict)
g = pyb.Pin("LeftMotorDir", pyb.Pin.OUT_OD)
可以使用自己的名称进行查询
pin = pyb.Pin("LeftMotorDir")
用户也可以给GPIO增加自己的函数
def MyMapper(pin_name):
if pin_name == "LeftMotorDir":
return pyb.Pin.cpu.A0
pyb.Pin.mapper(MyMapper)
因而可以使用自定义的名称进行GPIO调用
LED
侦侦拍rv1106,板上只有一个LED,因而id可以使用1~4任意值
LED位于TF卡座旁,上电后,系统默认点亮LED,用来指示系统运行状态
使用on,off控制闪烁
from pyb import LED
led = LED(1)
led.toggle()
global flag
flag = 0
def loop():
global flag
if(flag <= 0) :
led.on()#亮
flag = 1
else:
led.off()#灭
flag = 0
控制LED闪烁
from pyb import LED
led = LED(1)
def loop():
led.toggle()
马达控制
舵机控制
舵机按接口分为数字接口和模拟接口的舵机。数字接口使用串口或I2C作为通信协议;模拟接口舵机通过设置PWM的占空比来控制角度。
数字舵机参考I2C章节。
下面针对具有3线(地,电源,信号)的模拟舵机。其使用的是硬件的PWM来驱动舵机的角度,znzpi引出了3个硬件PWM。
分别是PWM1,PWM5,PWM6,具体的分别可以参考接口图。
import image
import sensor
import ai
from pyb import Servo
sensor.reset()
s1 = Servo(1)
s2 = Servo(2)
s1.angle(30)
s2.angle(0)
cnt1 = 30
cnt2 = 0
def loop():
img = sensor.snapshot()
img.draw_rectangle((1175,412,513,244), color=(0,255,0), thickness=4)
global cnt1
global cnt2
global s2
global s1
global uart3
s1.angle(cnt1)
s2.angle(cnt2)
cnt1 += 10
cnt2 += 10
if cnt1 > 180 :
cnt1 = 0
if cnt2 > 180 :
cnt2 = 0
I2C
I2C是用于设备间通信的两线串行协议。由时钟线SCL和数据线SDA组成。
znzpi支持4组固定的I2C接口,编号为1,2,3,4。以及自定义复用GPIO的I2C接口,使用编号8。
自定义接口默认SCL使用A7,SDA使用A8。
I2C可以创建的同时定义总线信息。用法如下:
from pyb import I2C
def loop():
i2c = I2C(1) # create on bus 1
i2c = I2C(1, I2C.MASTER) # create and init as a master
i2c.init(I2C.MASTER, baudrate=20000) # init as a master
i2c.init(I2C.SLAVE, addr=0x42) # init as a slave with given address
i2c.deinit()
可以通过打印i2c来查看相关的信息
作为I2C从设备,可以按如下方式来发送或接收数据
i2c.send('abc') # send 3 bytes
i2c.send(0x42) # send a single byte, given by the number
data = i2c.recv(3) # receive 3 bytes
需要接收数据前,需要先定义一个接收的bytearray类型的buffer
data = bytearray(3) # create a buffer
i2c.recv(data) # receive 3 bytes, writing them into data
作为主设备,在使用前需要先定义自身的地址
i2c.init(I2C.MASTER)
i2c.send('123', 0x42) # send 3 bytes to slave with address 0x42
i2c.send(b'456', addr=0x42) # keyword for address
作为主设备的其他功能如下:
i2c.is_ready(0x42) # check if slave 0x42 is ready
i2c.scan() # scan for slaves on the bus, returning
# a list of valid addresses
i2c.mem_read(3, 0x42, 2) # read 3 bytes from memory of slave 0x42,
# starting at address 2 in the slave
i2c.mem_write('abc', 0x42, 2, timeout=1000)
from pyb import I2C
#i2c = I2C(1) # create on bus 1
i2c = I2C(3, I2C.MASTER) # create and init as a master
i2c.init(I2C.MASTER, baudrate=20000,addr=6) # init as a master
def loop():
#i2c.init(I2C.SLAVE, addr=0x42) # init as a slave with given address
#i2c.deinit()
code = [0xFF,0x1]
i2c.send(bytes(code))
angl = [0x1,0xff,0xff]
i2c.send(bytes(angl))
UART串口
默认有2组UART口引出分别是UART1和UART3,UART1和UART3可以单独使用。 也可以将485芯片焊接上作为485接口使用。
UART实现了标准的UART/USART全双工串口通信协议。使用2线RX和TX。
UART的使用和I2C十分相似,主要在初始化参数上有一些不同。
from pyb import UART
uart = UART(3, 9600) # init with given baudrate
uart.init(9600, bits=8, stop=1, parity=None) # init with given parameters
其中的bit可以是8或9,stop可以是1或2,parity可以是0(偶校验),1(奇校验)
uart.any() # returns True if any characters waiting
TF卡
TF卡的管脚已经通过排针引出,在使用板上的TF卡槽的时候,这些排针引脚不可用做GPIO。
如果有TF卡插入,控制程序init.py会优先尝试从TF卡中读取; 其次是znzpi的flash的用户数据部分,也就是插入usb otg后userdata的cam_conf/jobs目录中读取; 再次从znzpi的内部flash中读取,最后从运行的固件程序相同目录下读取。
主控程序init.py的写入也遵循相同的路径。
当插入TF卡后,会在系统中生成一个 /sdcard 目录,格式化为fat32格式TF卡,可以在程序中直接读取其中的内容。
USB
USB接口为OTG,可以作为系统调试和固件下载G。板上是一个TYPE-C接口,正插和反插的功能不同,
一面作为系统调试的串口,接的是调试串口UART2,另外一面接的是OTG,在上电或复位的时候按住FEL按键,可以下载固件。 进入系统后,会生成一个U盘和一个python程序的调试串口。在znzpi_ide里面打开对应的串口,会得到python程序的调试输出, 其中包括python系统的输出,也包括用print函数打印的调试信息。
LCD
开发板已经将LCD屏的驱动配置完成,通过板上的屏接口和屏连接。 配套的lcd屏幕可以在淘宝店铺中购买。
在lcd屏上显示实时图像,并画框
import image
import sensor
from pyb import LCD
sensor.reset()
lcd = LCD('tft')
roi = (20,20,200,100)
def loop():
img = sensor.snapshot()
lcd.display(img)
lcd.rect(roi=roi)
将人脸识别的结果,显示到lcd屏上
import image
import sensor
import ai
from pyb import LCD
sensor.reset()
ml = ai.load(ai.FACE_DETECT)
lcd = LCD('tft')
roi = (20,20,200,100)
def loop():
img = sensor.snapshot()
lcd.display(img)
out = ml.forward(img,roi=roi)
for it in out:
print(it.rect())
img.draw_rectangle(it.rect(),color=(255,0,0), thickness=4)
lcd.rect(roi=it.rect())
PWM
开发板通过排针已经将2个硬件支持的PWM引出。
from pyb import Pwm
def loop():
p0 = Pwm(0)
print(p0)
p0.pulse_width(10000) #set pulse width in microseconds,(10000microsec,100KHz)
#p0.peroid(10000) # same as pulse_width set pulse width in microseconds
p0.duty(5000)#set pulse duty in microseconds
DA和AD
adc支持0和1两个通道, 0通道对应板上P9,1通道对应板上P10
adc的精度为10bit,转换为电压需要按*3.3/1024计算得到。
from pyb import ADC
adc = ADC(0)
def loop():
# ADC 10-bits 精度,1024个值
print("ADC = %fv" % ((adc.read() * 3.3) / 1024))
读取cpu温度
from pyb import ADCAll
temp = ADCAll(0)
def loop():
print("tempture = %f" % (temp.read_core_temp() ))
RTC
侦侦拍板内置RTC,可以使用相关的功能进行设置或读取。
from pyb import RTC
rtc = RTC()
rtc.datetime((2013, 7, 9, 2, 0, 0, 0, 0))
def loop():
print(rtc.datetime())
WIFI
RTL8723 WFIF和蓝牙
znzpi使用RTL8723模块WIFI和蓝牙芯片。可以在软件上设置相应的SSID和密码。也可以在/userdata/cam_conf/voc_config.json中修改。
使用sta模式连接wifi路由器的示例如下:
import network
SSID='youvtec' # Network SSID
KEY='88888888' # Network key
print("Trying to connect... (may take a while)...")
wlan = network.WIFI()
wlan.connect(SSID, key=KEY, security=wlan.WPA_PSK)
def loop():
#get IP
print(wlan.ifconfig())
#scan ap
aps = wlan.scan()
print(aps)
增加自己的wifi驱动
如果需要使用自己的wifi模组,需要使用交叉编译工具,编译模组的linux驱动,并放到 userdata/bin/目录中, 修改install_wifi.sh和install_ap.sh,加载对应的驱动xxx.ko 并修改对应的设置。
在程序中使用wlan.connect()设置的SSID和key会被写入到/userdata/cam_conf/vod_config.json中的wifista字段。 并调用/userdata/bin/install_wifi.sh脚本。 在install_wifi脚本中会读取/userdata/cam_conf/vod_config.json中的wifista字段获取到ssid和password(key) 并写入/userdata/cam_conf/wpa_supplicant.conf配置文件中, 在install_wifi脚本中调用wpa_supplicant,并使用上述对应的配置文件。 在这里要特别注意不同的wifi模块的不同要求,比如mt7601,在sta模式,需要将mt7601u.bin放入到/lib/fireware/目录中, 这就需要在install_wifi.sh脚本中进行相应的处理。
ssid和key一定要正确,否则也不会连接成功。
在install_wifi.sh中,使用bonding的模式,将eth0和wlan0进行负载均衡处理,是为了保证发送的图传数据具有单一地址。
红外热成像
znzpi可以通过I2C,外接mlx90640热成像传感器。 将mlx90640的scl和sda接入对应的i2c管脚,默认使用I2C1。 scl和sda管脚需要用1k电阻上拉到3.3V。
支持的函数如下:
fir.init(type,refresh,resolution,id)
type: FIR_SHIELD,FIR_MLX90620,FIR_MLX90621,FIR_MLX90640,FIR_AMG8833
refresh: 帧率
resolutin: 分辨率
id: i2c id,可以取的值(1,2,3,4)分别对应i2c的SCL和SDA
fir.deinit()
释放所有资源,包括i2c占用的gpio。
fir.width()
返回图像宽度
fir.height()
返回图像高度
fir.type()
返回sensor类型
fir.refresh()
返回图像帧率
fir.resolution()
返回ADC的bit数
fir.read_ta()
返回检测到的温度
fir.read_ir()
读取热成像图像
fir.draw_ta()
显示检测到的温度
fir.draw_ir(img,ir,alpha,scale)
绘制热成像图像到img中
img:要写入的图像
ir:热成像图像
alpha:透明度
scale:缩放系数
fir.snapshot(pixformat,copy_to_fb)
抓取一帧热成像图像,并返回一个image。
formart:保存图像格式,默认YUV420
img:copy到已有image
mlx90640
import image, time, fir
fir.init(type=fir.FIR_MLX90640, refresh=4,id=5) # 16Hz, 32Hz or 64Hz.
# FPS clock
clock = time.clock()
print(clock)
def loop():
clock.tick()
img = fir.snapshot()
img.draw_image(img,(100,20),x_scale=10.0,y_scale=10.0)
# Print FPS.
print(clock.fps())
图传控制
高级编程
修改相机设置
修改相机的设置,有两种方式:
方式1: 相机所有的设置通过放在userdata/cam_conf/下配置文件vod_config.json实现的,可以通过修改此文件来修改相机的运行方式。 包括网络相关的ip,wifi;图传编码通道和码流设置; 这种方式在相机无法联网,通过usb的otg连入电脑,可以看到MTP盘的情况下,可以很方便的修改相机设置。
方式2:在可以通过网络访问相机的情况下,可以在浏览器中输入相机ip,并在设置中修改相机的设置。
处理HTTP请求
在程序中可以自己定义一个http响应接口,在相应的回调函数中,处理业务,并返回处理结果。
使用http.response和http.broadcast返回数据,如果在回调函数中没有调用这些返回的数据。 znzpi会返回默认的字符串success,作为默认数据,来防止浏览器等客户端,长时间等待和反复请求。
import image
import sensor
import http
sensor.reset()
def stats_get(opt):
img = sensor.snapshot()
img.draw_rectangle((1429,162,250,140), color=(0,255,0), thickness=4)
thr = (120,159,90,117,104,156)
blobs = img.find_blobs([thr],roi=(1429,162,250,140))
for ln in blobs :
img.draw_rectangle(ln.rect(),color=(255,0,0), thickness=4)
http.response('ok')
http.get('stats',stats_get)
def loop():
print('main')
import image
import sensor
import http
sensor.reset()
#ht = http.httpd()
def stats_get(opt):
print(opt)
http.response('stats ok')
http.get('stats',stats_get)
#print(ht)
def loop():
print('main')
#print(ht)
stats_get(1)
类似的http请求处理还有 http.post http.put http.del 使用方法和http.get类似
发送HTTP请求
程序中可以向其他的web服务器发送GET/POST请求。
import image
import sensor
from zrequest import request
sensor.reset()
def loop():
img = sensor.snapshot()
res = request.get('http://www.youvtec.com')
print(res.text)
res = request.post('http://www.youvtec.com','test data')
#发送图像,作为示例,第三个参数可以省略,默认会加Content-type:image/jpeg
res = request.image('http://www.youvtec.com',img,'Content-type:image/jpeg')
向阿里云 AOSS 发送图片
程序中可以向阿里云AOSS发送请求,将图片存储在其AOSS空间。
AOSS的详细文档参考
import image
import sensor
from zrequest import aoss
sensor.reset()
#使用临时授权作为输入
reaos = aoss("https://crmeb-test.mer.chuidiaotop.com/api/xxx")
#查看aoss授权是否正确
print(reaos)
def loop():
#获取当前图像
img = sensor.snapshot()
#发送图像到AOSS,第二个参数为图像名,可以省略,
#默认会使用当前时间生成 year_month_day_hour_min.jpg
reaos.image(img)
算法移植
当已有的图像处理或ai处理不满足需求时,可以增加自己的算法,或移植其他算法。
在使用c/c++代码的时候需要安装交叉编译环境,并将编译后的动态库或静态库,加入到工程中。
也可以使用python代码写自己的算法库,方便共享。
使用python模块
python模块支持:
-
内置模块
-
.py脚本
-
C编译后的模块.mpy
模块的搜索路径:
-
~/.micropython/lib
-
/usr/lib/micropython
-
/userdata/cam_conf/jobs
通常将需要使用的模块放在/userdata/cam_conf/jobs下,这个目录在虚拟的u盘中可以找到
增加自己的算法
增加到python的模块中
编译
更新算法固件
修改记录
| 版本 | 修改内容 | 修改日期 |
|---|---|---|
0.2.4 |
增加使用方式章节 |
2024.3.6 |
0.2.3 |
增加AI训练模块 |
2023.10.15 |
0.2.2 |
增加wifi/tf/http模块 |
2022.10.11 |
0.2.1 |
增加image模块 |
2022.6.19 |
0.2.0 |
增加_applet.exec() |
2022.6.10 |
0.1.1 |
增加脚本高级编程 |
2020.12.1 |
0.1.0 |
初始版本 |
2018.6.8 |